悅數(shù)圖數(shù)據(jù)庫
行業(yè)首創(chuàng) ,!Graph RAG:基于知識圖譜的檢索增強技術(shù)與優(yōu)勢對比(附 Demo)

身處信息爆炸時代,,如何從海量信息中獲取準(zhǔn)確全面的搜索結(jié)果,,并以更直觀,、可讀的方式呈現(xiàn)出來是大家期待達(dá)成的目標(biāo),。傳統(tǒng)的搜索增強技術(shù)受限于訓(xùn)練文本數(shù)量,、質(zhì)量等問題,,對于復(fù)雜或多義詞查詢效果不佳,,更無法滿足 ChatGPT 等大語言模型應(yīng)用帶來的大規(guī)模,、高并發(fā)的復(fù)雜關(guān)聯(lián)查詢需求,。
在此背景下,悅數(shù)圖數(shù)據(jù)庫率先實現(xiàn)了與 Llama Index,、LangChain 等大語言模型框架的深度適配并在行業(yè)內(nèi)首次提出了 Graph RAG(基于圖技術(shù)的檢索增強)的概念,,利用知識圖譜結(jié)合大語言模型(LLM)為搜索引擎提供更全面的上下文信息,可以幫助用戶以更低成本獲得更智能,、更精準(zhǔn)的搜索結(jié)果,。目前,悅數(shù)圖數(shù)據(jù)庫推出的這項技術(shù)在與向量數(shù)據(jù)庫結(jié)合的領(lǐng)域也獲得了相當(dāng)不錯的效果,。
今天我們就一起來了解下什么是 Graph RAG 以及它與其他 RAG 技術(shù)的對比,,也歡迎進(jìn)入 悅數(shù)圖數(shù)據(jù)庫 官網(wǎng),,通過 Demo 直觀感受這一功能。
傳統(tǒng)檢索增強技術(shù)的瓶頸:缺少訓(xùn)練數(shù)據(jù),,文本理解不足
在傳統(tǒng)的搜索引擎中,檢索結(jié)果通常是基于關(guān)鍵詞的匹配,。而隨著用戶對搜索精確度和詞匯聯(lián)想能力要求的提高,,傳統(tǒng)的搜索結(jié)果往往難以滿足用戶的實際需求,尤其是在處理復(fù)雜的問題和長尾查詢時,,效果會明顯降低,。
為了解決這類問題,RAG 搜索增強技術(shù)應(yīng)運而生,。RAG (Retrieval-Augmented Generation),,指的是通過 RAG 模型來對搜索結(jié)果進(jìn)行增強的過程。具體來說,,它是將檢索技術(shù)和語言生成技術(shù)相結(jié)合來增強生成過程的一種技術(shù),,可以幫助傳統(tǒng)搜索引擎生成更加準(zhǔn)確、相關(guān)和多樣化的信息來滿足用戶的需求,。
而為了使搜索結(jié)果更精準(zhǔn),,RAG 技術(shù)仍然面臨訓(xùn)練數(shù)據(jù)和文本理解的挑戰(zhàn):
訓(xùn)練數(shù)據(jù):RAG 技術(shù)需要大量的數(shù)據(jù)和計算資源來訓(xùn)練和生成模型,尤其是在處理多語言和復(fù)雜任務(wù)時,,但是互聯(lián)網(wǎng)上文本的質(zhì)量和準(zhǔn)確性是有限的,,訓(xùn)練數(shù)據(jù)的不足會直接影響生成內(nèi)容的質(zhì)量
文本理解:RAG 需要理解查詢的意圖,但是對于復(fù)雜的查詢或者多義詞查詢,,RAG 可能會出現(xiàn)歧義或不確定性,,從而影響生成的質(zhì)量
因此,如何找到更強大的檢索增強技術(shù),,以更高效率獲得更符合搜索者的預(yù)期的搜索結(jié)果的問題就顯得更迫在眉睫,。
什么是 Graph RAG:基于知識圖譜的檢索增強技術(shù)
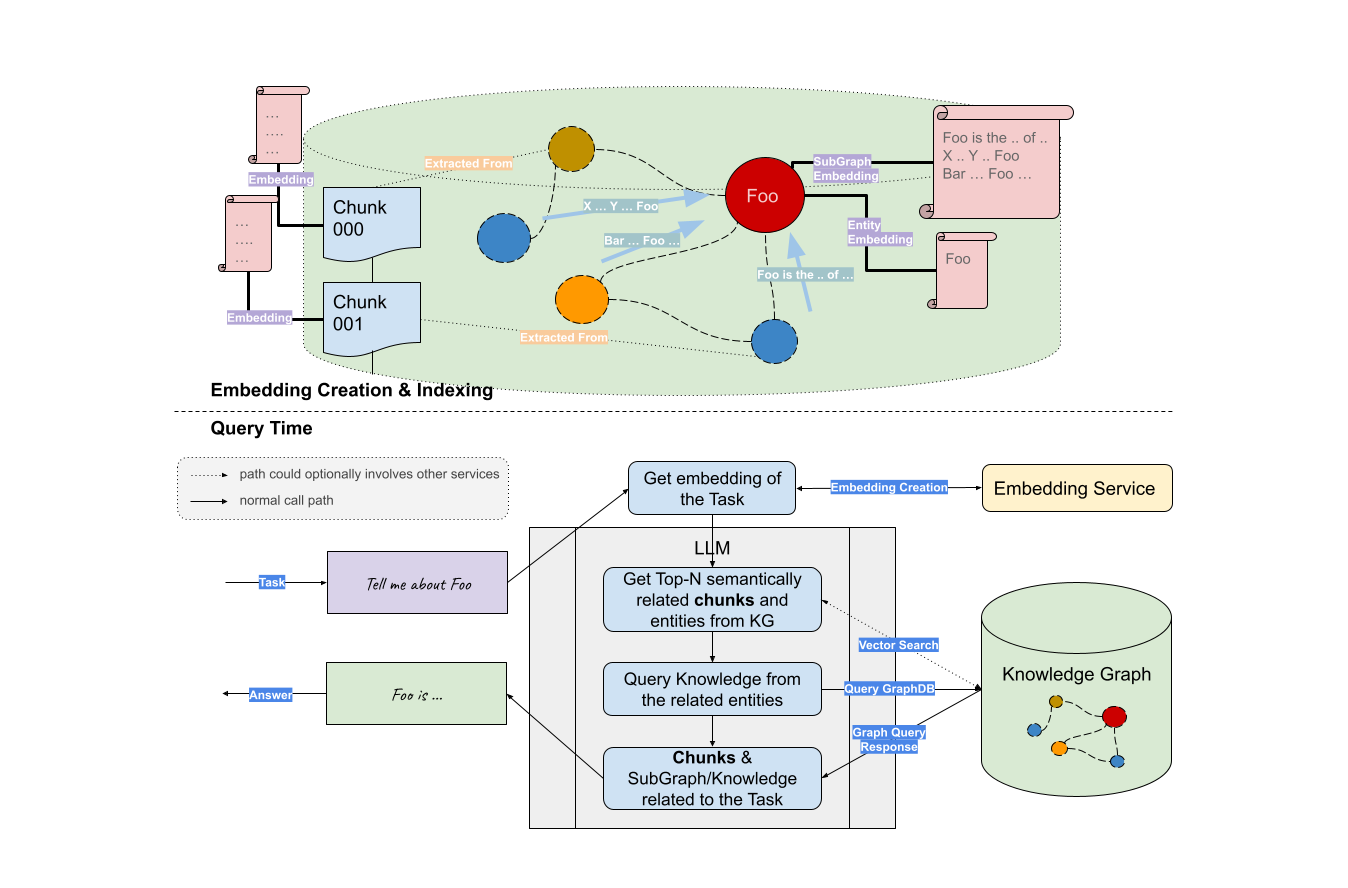
「Graph RAG」是由悅數(shù)圖數(shù)據(jù)率先提出的概念,它是一種基于知識圖譜的檢索增強技術(shù),,通過構(gòu)建圖模型的知識表達(dá),,將實體和關(guān)系之間的聯(lián)系用圖的形式進(jìn)行展示,然后利用大語言模型 LLM(Large Language Model)進(jìn)行檢索增強,。
在之前 和 Llama Index 的直播研討會 中我們提到,,圖數(shù)據(jù)庫憑借圖形格式組織和連接信息的方式,天然適合存儲及表達(dá)復(fù)雜的上下文信息,。通過圖技術(shù)構(gòu)建知識圖譜提升 In-Context Learning 的全面性為用戶提供更多的上下文信息,,能夠幫助大語言模型(LLM)更好地理解實體間的關(guān)系,提升自己的表達(dá)和推理能力,。
Graph RAG 將知識圖譜等價于一個超大規(guī)模的詞匯表,,而實體和關(guān)系則對應(yīng)于單詞,。通過這種方式,Graph RAG 在檢索時能夠?qū)嶓w和關(guān)系作為單元進(jìn)行聯(lián)合建模,,從而更準(zhǔn)確地理解查詢意圖,,并提供更精準(zhǔn)的檢索結(jié)果。
Demo 演示:檢索強化效果對比:「悅數(shù)」官網(wǎng)可直接在線體驗
下面我們就通過 Demo 演示來直觀比較下 Graph RAG 與 Vector RAG,、Text2Cypher 這三種檢索增強技術(shù)的區(qū)別和對比——
Vector RAG 與 Graph + Vector RAG 的對比
首先是 Vector RAG(向量檢索) 與 Graph + Vector RAG(圖技術(shù)增強的向量檢索)的對比,。
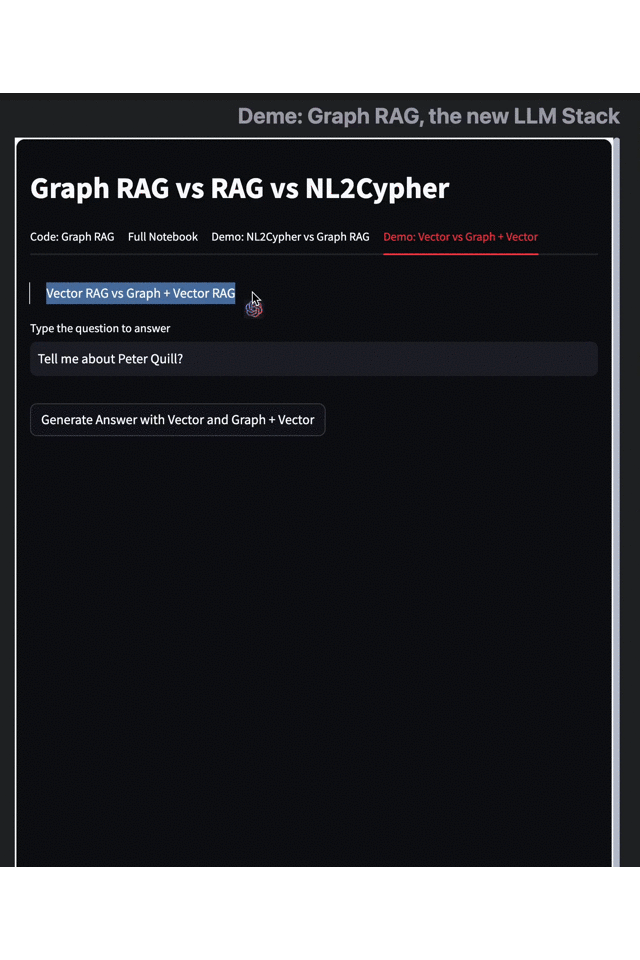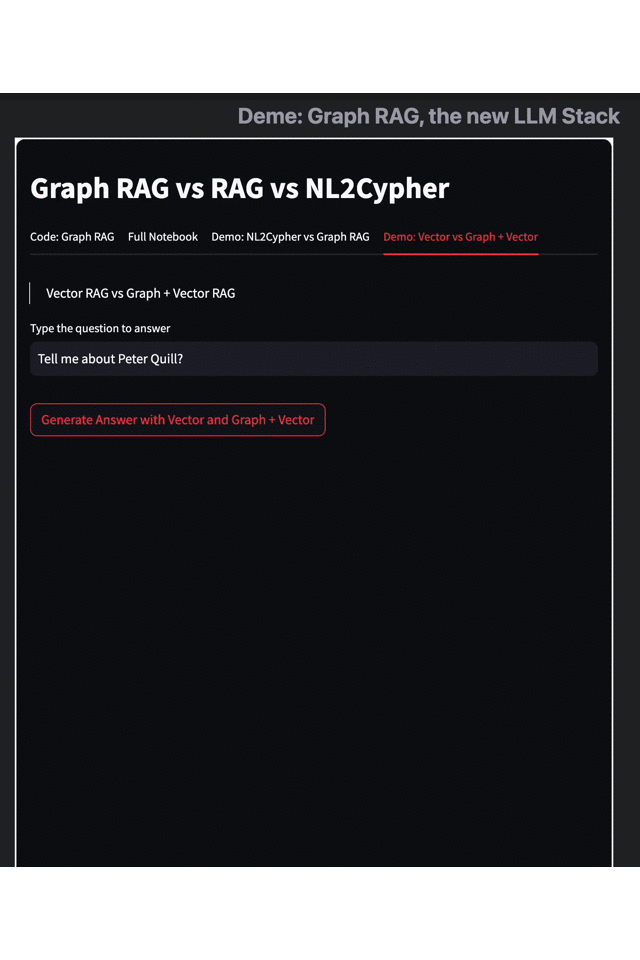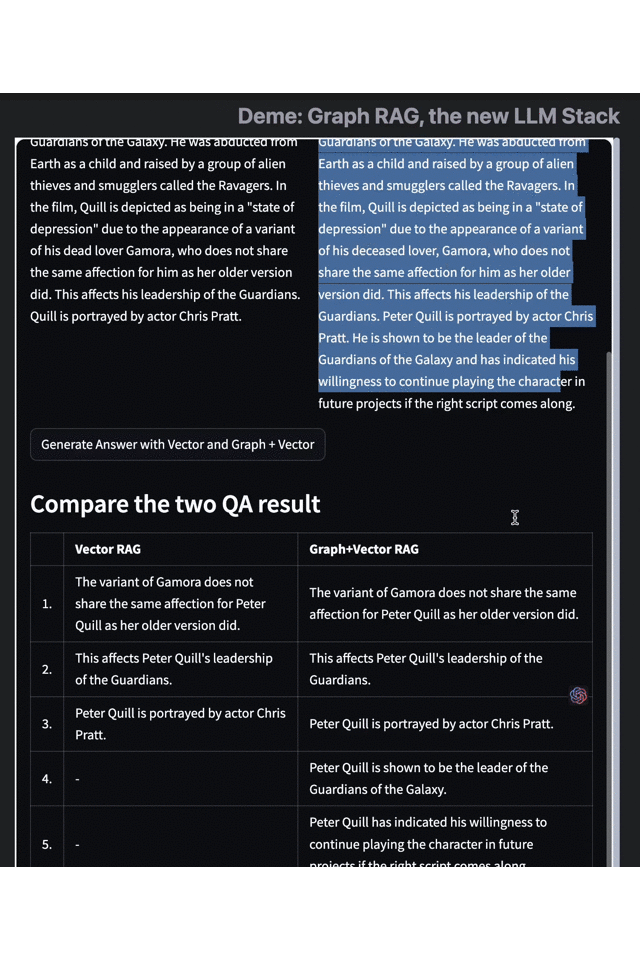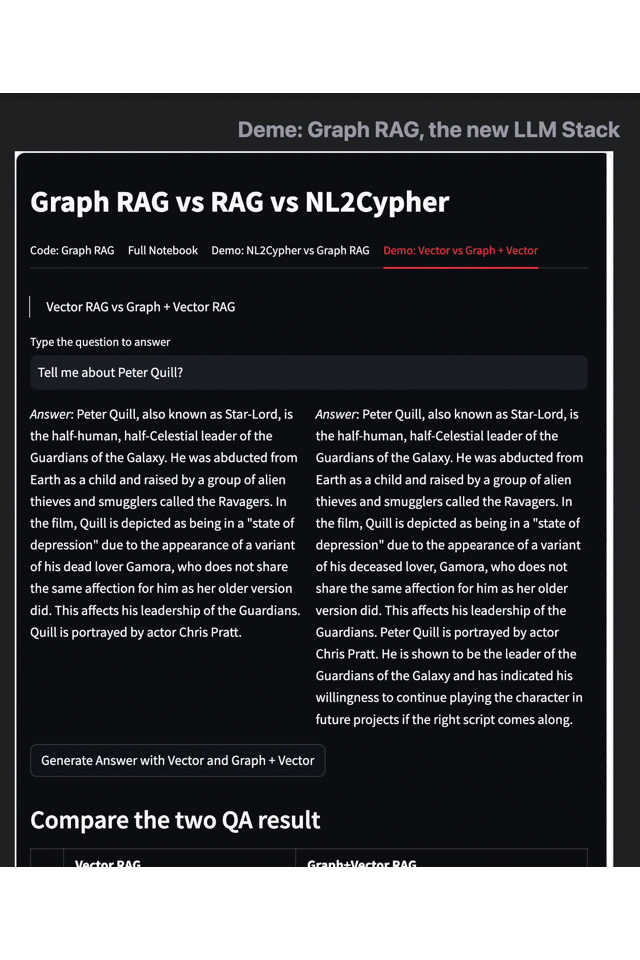
- 左:Vector RAG 右:Graph + Vector RAG
以《銀河護(hù)衛(wèi)隊 3》的數(shù)據(jù)集為例,,當(dāng)我們詢問“彼得·奎爾的相關(guān)信息”時,,單獨使用向量檢索引擎只給出了簡單的身份、劇情,、演員信息,,而當(dāng)我們使用 Graph RAG 增強后的搜索結(jié)果,則提供了更多關(guān)于主角技能,、角色目標(biāo)和身份變化的信息——在這個例子中我們不難看出,, Graph RAG 的方法有效補充了 Embedding、向量搜索等傳統(tǒng)手段的不足,。
Graph RAG 與 Text2Cypher 的對比
基于圖譜的 LLM 的另一種有趣方法是 Text2Cypher,,即自然語言生成圖查詢。這種方法不依賴于實體的子圖檢索,,而是將任務(wù)/問題翻譯成一個面向答案的特定圖查詢,,和我們常說的 Text2SQL 本質(zhì)是一樣的。
Text2Cypher 和 Graph RAG 這兩種方法主要在其檢索機制上有所不同,。Text2Cypher 根據(jù)知識圖譜的 Schema 和給定的任務(wù)生成圖形模式查詢,,而 (Sub)Graph RAG 獲取相關(guān)的子圖以提供上下文。兩者都有其優(yōu)點,,大家可以通過這個 demo ,,更直觀理解他們的特點:

- 左:Text2Cypher 右:Graph RAG
我們可以看到兩者的圖查詢模式在可視化下是有非常清晰的差異的,基于 Graph RAG 實現(xiàn)的檢索明顯呈現(xiàn)出更豐富的結(jié)果,。用戶不僅獲得了最基礎(chǔ)的介紹信息,,更能得到“彼得·奎爾是銀河護(hù)衛(wèi)隊的領(lǐng)導(dǎo)者”、“這個角色暗示自己將在續(xù)集中回歸”以及角色性格等一系列基于關(guān)聯(lián)搜索和上下文進(jìn)行推理得出的結(jié)果,。
悅數(shù)圖數(shù)據(jù)庫:率先實現(xiàn) LLM 適配,一鍵構(gòu)建企業(yè)專屬知識圖譜應(yīng)用
悅數(shù)圖數(shù)據(jù)庫不僅是國內(nèi)首家提出 Graph RAG 概念的廠商,,也率先實現(xiàn)了與大語言模型框架 Llama Index ,、LangChain 等的深度適配,因此開發(fā)者可以專注于 LLM 的編排邏輯和 pipeline 設(shè)計,,而不用親自處理很多細(xì)節(jié)的抽象與實現(xiàn),,一站式生成高質(zhì)量,、低成本的企業(yè)級大語言模型應(yīng)用。
Graph RAG 技術(shù)的出現(xiàn)可以說是為海量信息處理和檢索帶來了全新的思路,。通過將知識圖譜,、圖存儲集成到大語言模型(LLM) 技術(shù)棧中,Graph RAG 把上下文學(xué)習(xí)推向了一個新的高度,。目前,,用戶基于悅數(shù)圖數(shù)據(jù)庫 僅需要 3 行代碼就可以輕松搭建 Graph RAG,甚至整合更復(fù)雜的 RAG 邏輯,,比如 Graph+Vector RAG,。
選擇相信隨著圖技術(shù)和深度學(xué)習(xí)算法的進(jìn)一步發(fā)展,Graph RAG 技術(shù)在信息處理和檢索領(lǐng)域的應(yīng)用也會越來越廣泛,。歡迎大家點擊【聯(lián)系我們】獲取悅數(shù)圖數(shù)據(jù)的免費試用機會,,輕松構(gòu)建您的專屬知識圖譜應(yīng)用!
- 相關(guān)推薦:




