首頁>博客>新聞資訊>演講回顧丨杭州悅數(shù) CTO 葉小萌:圖數(shù)據(jù)庫發(fā)展新航向——擁抱 GQL,,融合 HTAP,,攜手 AI
演講回顧丨杭州悅數(shù) CTO 葉小萌:圖數(shù)據(jù)庫發(fā)展新航向——擁抱 GQL,融合 HTAP,,攜手 AI
本文為杭州悅數(shù) CTO 葉小萌在“標準+智能:新質(zhì)生產(chǎn)力的原動力”悅數(shù)圖數(shù)據(jù)庫新產(chǎn)品發(fā)布會上的演講回顧,,主題為:《新標準、新期待:展望圖數(shù)據(jù)庫發(fā)展的關鍵方向》
各位嘉賓,、悅數(shù)圖數(shù)據(jù)庫的用戶以及線上的觀眾朋友們大家好,!今天很高興有機會和大家分享我對數(shù)據(jù)庫,尤其是圖數(shù)據(jù)庫的感悟與想法,。
GQL 的誕生推動圖數(shù)據(jù)庫的發(fā)展
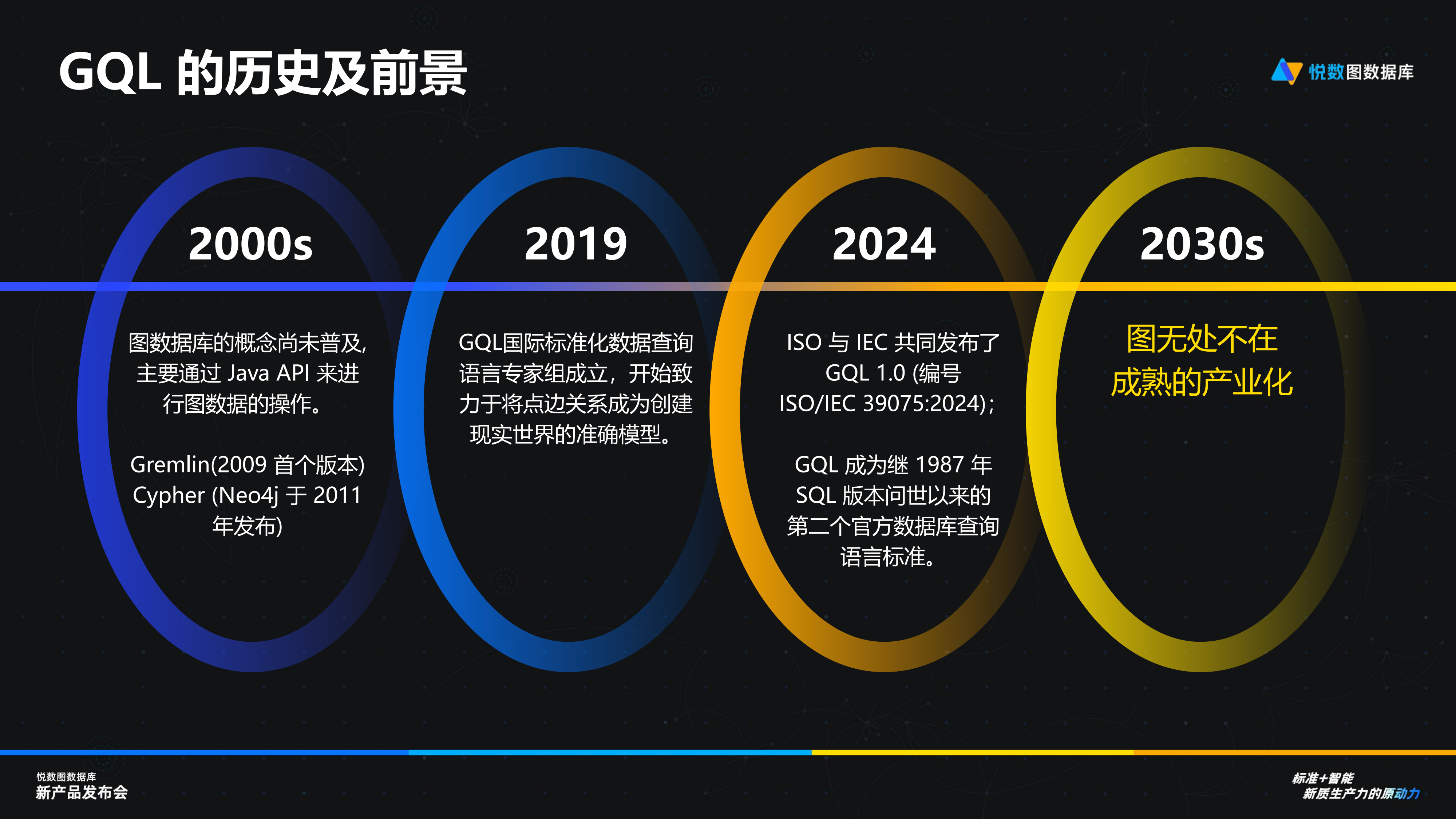
在 2000 年前后,,圖數(shù)據(jù)庫的概念尚未普及,當時主要通過 Java API 進行相關操作,。直到 2009 年,,Apache TinkerPop 規(guī)范定義的 Gremlin 查詢語言首次發(fā)布;兩年后的 2011年,,Neo4j 推出了更加廣為人知的 Cypher 圖查詢語言,。在圖數(shù)據(jù)庫的后續(xù)發(fā)展中,雖然越來越多的廠商為圖數(shù)據(jù)庫增添了豐富的功能,,但多樣的查詢語言也給用戶帶來了困擾,。在選擇產(chǎn)品時,用戶不僅需要考慮產(chǎn)品本身的性能,,還必須評估查詢語言的易學性和掌握難度,。此外,如果所選產(chǎn)品所使用的查詢語言在幾年后不再被廣泛采用,,替換成本將會非常高,。這種情況直接影響了圖數(shù)據(jù)庫在業(yè)界的接受度。
直到 2019 年,,國際標準化組織(ISO)成立了專門工作組,,致力于制定圖數(shù)據(jù)庫查詢語言的標準。經(jīng)過近五年的討論,,2024 年 4 月,,ISO 正式發(fā)布了國際標準圖查詢語言 ——Graph Query Language(GQL)。GQL 標準的發(fā)布標志著圖數(shù)據(jù)庫技術走向成熟的重要一步,。它不僅有助于提高圖數(shù)據(jù)庫的可操作性,,還降低了用戶的遷移成本,促進了圖數(shù)據(jù)庫技術的廣泛應用,。杭州悅數(shù)作為圖數(shù)據(jù)庫廠商也積極參與了標準的制定,,進一步增強了標準的權威性和實用性,悅數(shù)圖數(shù)據(jù)庫更是全球首款原生支持 GQL 的圖數(shù)據(jù)庫產(chǎn)品,。相信 GQL 的發(fā)布有望像當年 SQL 標準推動關系數(shù)據(jù)庫發(fā)展一樣,,推動圖數(shù)據(jù)庫的發(fā)展,,提升業(yè)界對圖數(shù)據(jù)庫的接受程度。我們有理由相信,,在 2030 年前后,,依托于 GQL 標準, 圖技術將全方位融入生活,,形成行業(yè)的結(jié)構化,、產(chǎn)業(yè)化。
圖數(shù)據(jù)庫與 HTAP:融合發(fā)展,,突破數(shù)據(jù)處理瓶頸
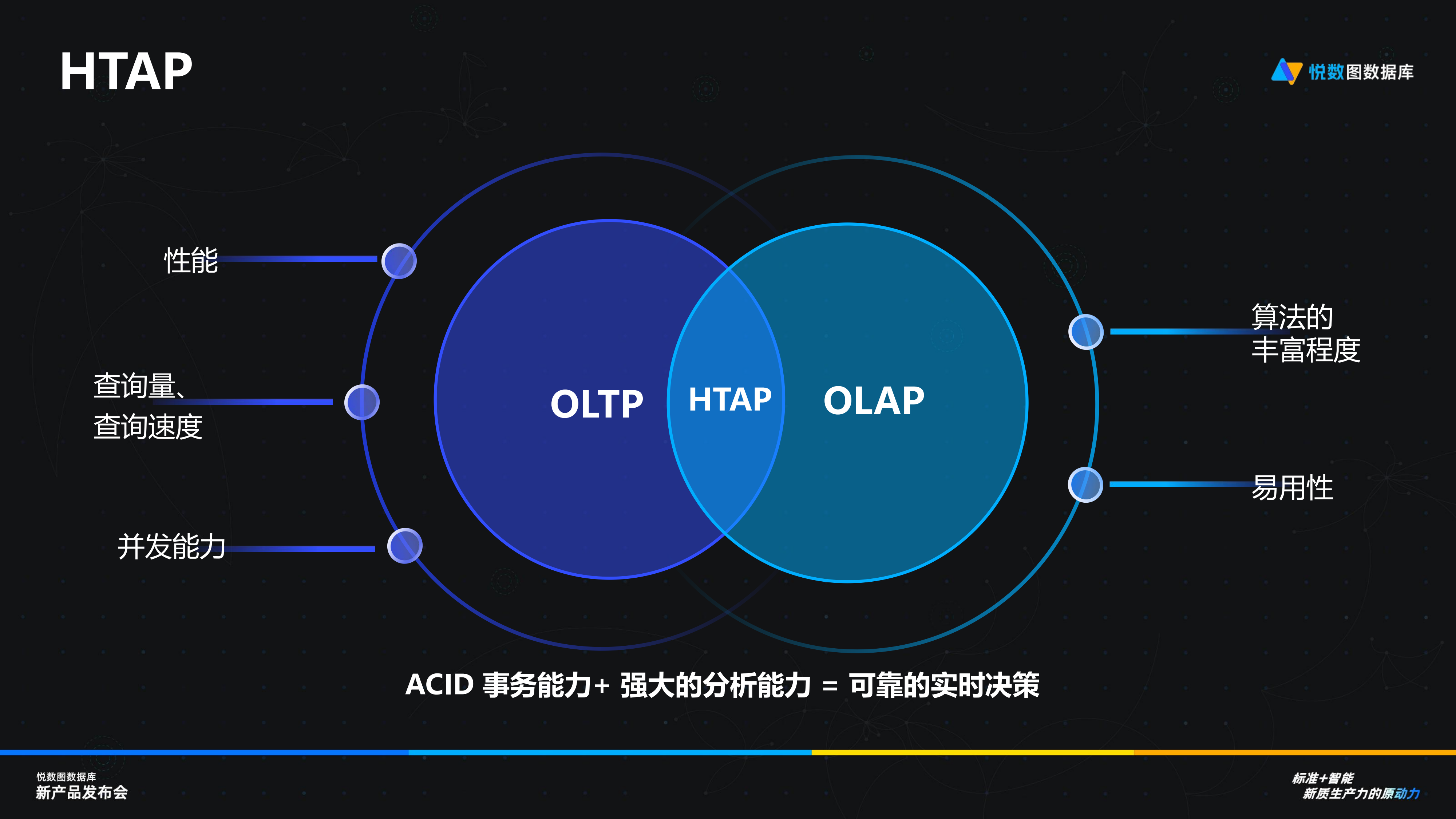
在數(shù)據(jù)庫領域,近年來出現(xiàn)了 HTAP 概念,,旨在將 OLTP(在線事務處理)和 OLAP(在線分析處理)功能整合于一個系統(tǒng)中,。在傳統(tǒng)企業(yè)架構中,OLTP 系統(tǒng)負責在線業(yè)務的數(shù)據(jù)修改和查詢,,而數(shù)據(jù)隨后會同步到后端數(shù)據(jù)倉庫以進行分析和挖掘,。然而,這種方式無論是傳統(tǒng)關系型數(shù)據(jù)庫還是圖數(shù)據(jù)庫,,往往都面臨高存儲成本和數(shù)據(jù)時效性的問題,。截至 2023 年,OLTP 和 OLAP 在的市場份額基本上各占一半,。然而,,在圖數(shù)據(jù)庫領域,分析需求的占比可能更高,。根據(jù)我們接觸到的市場情況,,分析需求可能占到 60% - 70%,而在線事務處理則占 30% - 40%,。
作為圖數(shù)據(jù)庫廠商,,我們希望能夠整合圖數(shù)據(jù)庫的交易與分析功能,實現(xiàn) HTAP 能力,。首先,,實現(xiàn)底層數(shù)據(jù)共享,以解決存儲和數(shù)據(jù)時效性的問題,;其次,,針對分析查詢,既然已經(jīng)有了 GQL 標準,,我們可以能夠使用它進行分析查詢,,就像使用 SQL 進行查詢一樣。此外,圖數(shù)據(jù)庫中存在許多算法,,而以往在不同系統(tǒng)中描述這些算法的難度較大,,對數(shù)據(jù)分析人員的要求也很高,。因此,,我們希望在 GQL 的基礎上,具備描述算法的能力,,從而真正實現(xiàn)查詢語言的統(tǒng)一,。因此我們認為基于標準的分布式 HTAP 系統(tǒng)是圖數(shù)據(jù)庫未來的重要發(fā)展方向。
圖數(shù)據(jù)庫與 AI :打破向量局限,,實現(xiàn)優(yōu)勢互補
2022 年底,OpenAI 發(fā)布了 3.0 大模型,,掀起了 AI 的熱潮,。如何有效地將私有數(shù)據(jù)與公共領域的知識模型結(jié)合,成為了一個重要的研究課題,。對于企業(yè)而言,,訓練專有的大模型不僅需要強大的計算能力,還對技術團隊和研發(fā)團隊提出了較高的要求,。相比之下,,RAG 技術將私有數(shù)據(jù)作為大模型的補充,避免了重新校正和訓練模型的復雜過程,,因此對技術能力的要求相對較低,。隨著大模型的不斷發(fā)展,基于向量數(shù)據(jù)庫的 RAG 解決方案也逐漸涌現(xiàn),。

然而,,基于向量數(shù)據(jù)庫的 RAG 存在顯著問題。私有數(shù)據(jù)本身具有內(nèi)在的關聯(lián)關系,,但向量數(shù)據(jù)庫無法有效地體現(xiàn)這些關系,。而用戶給到大模型的請求是按照 Token 來計算的,Token 越多,,計算量越大,,價格也越高,時間也越長,,RAG 因為缺少了關聯(lián)的知識,,會導致大量的計算資源的浪費和時間的浪費,且結(jié)果不夠精準,。
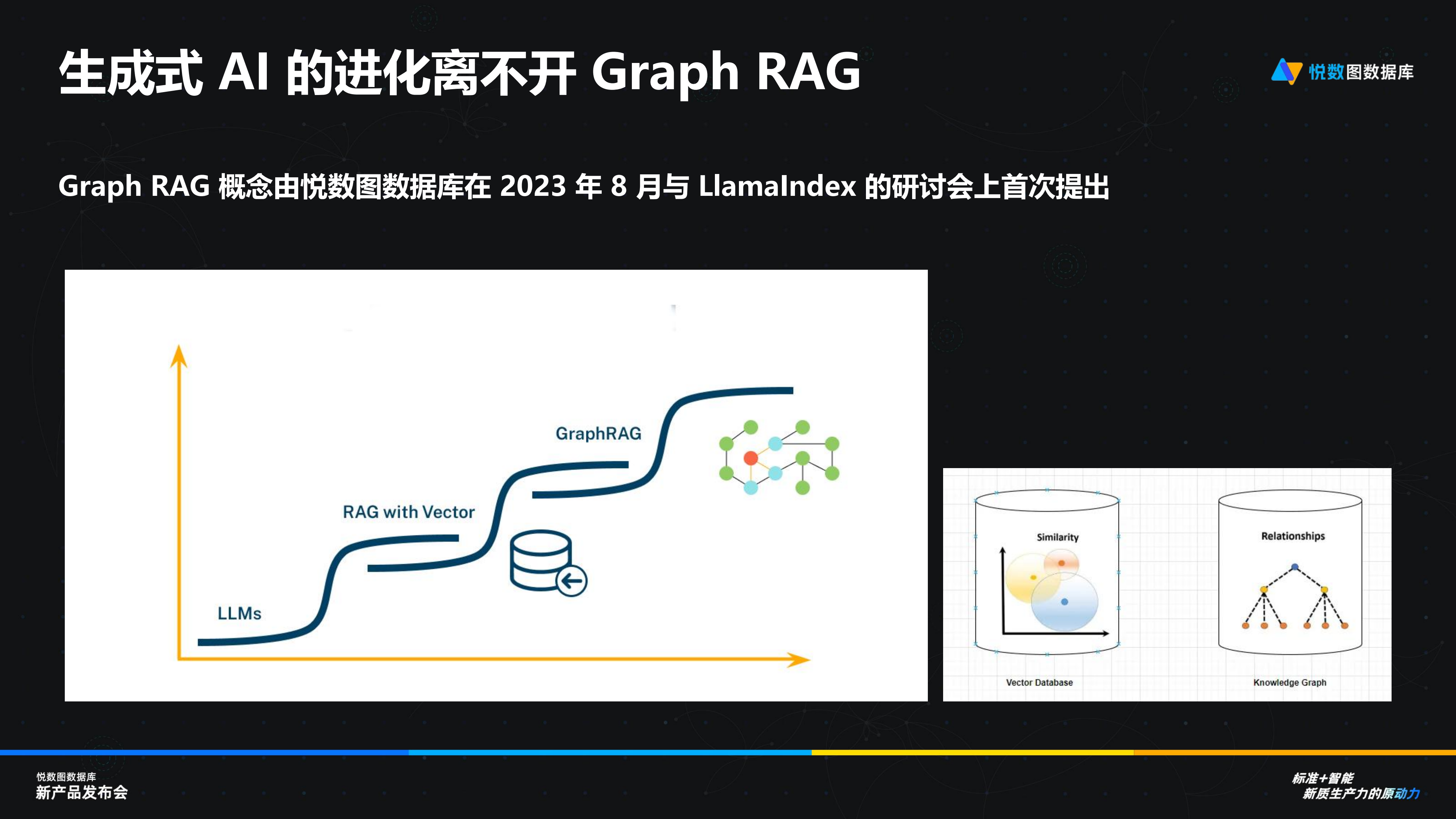
相比之下,,圖數(shù)據(jù)庫能夠更好地識別和保留這些關系,從而提高信息檢索的準確性和效率,。圖數(shù)據(jù)庫在處理復雜關系和大規(guī)模數(shù)據(jù)方面具有天然優(yōu)勢,,這對于 AI 的理解和推理能力至關重要,。
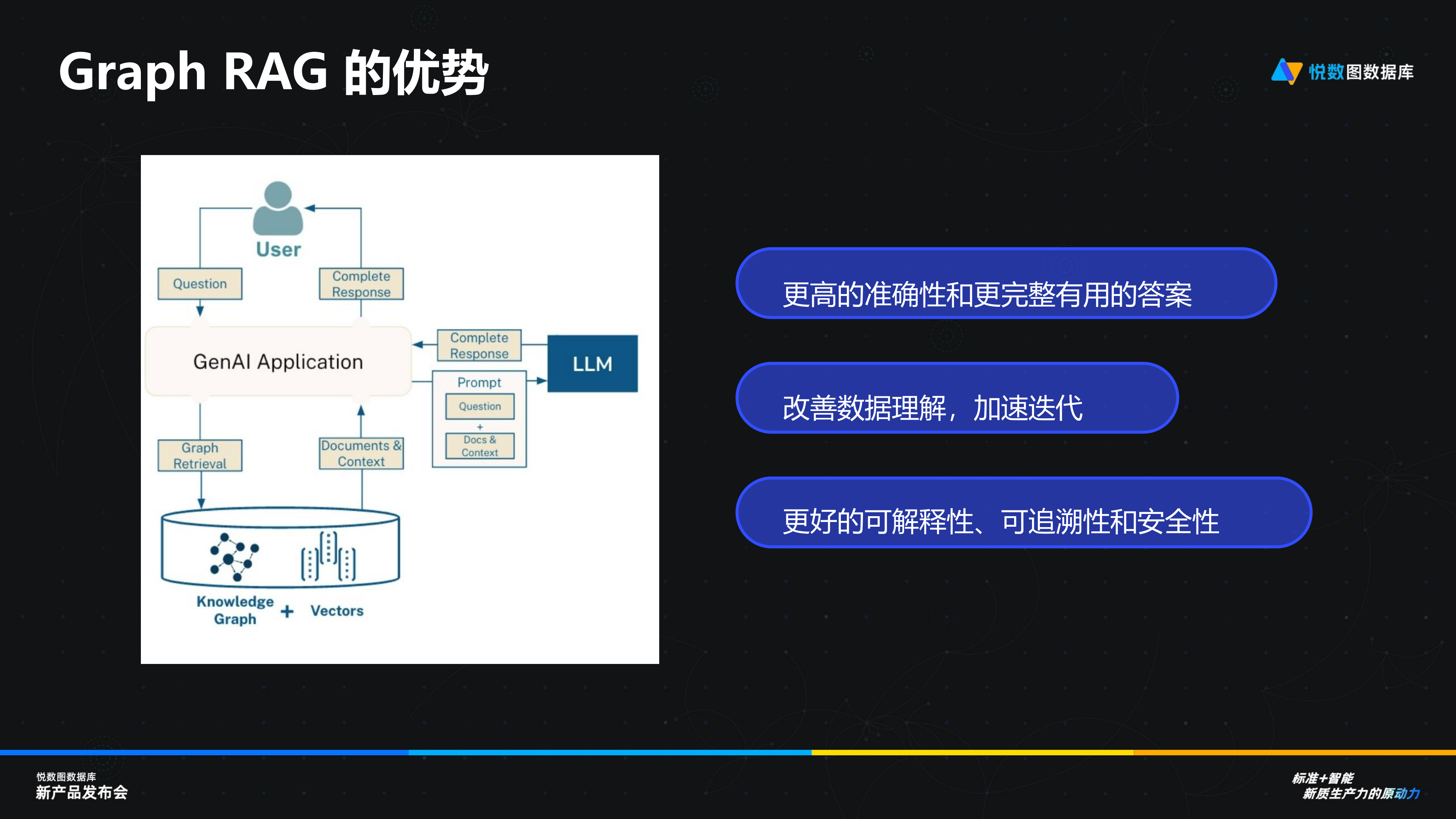
在 2023 年 8 月,我們提出用圖數(shù)據(jù)庫取代向量數(shù)據(jù)庫,,并與 LlamaIndex 社區(qū)合作推出 Graph RAG,。該方案通過提供更具上下文感知的能力和數(shù)據(jù)訓練的方法,緩解了傳統(tǒng)搜索增強技術的幻覺,,能夠區(qū)分像“保溫杯”和“保溫大棚”這種關鍵字相似但語義不同的內(nèi)容,,確保所提供的回復不僅精確,而且信息豐富,。今年上半年,,微軟開源的 Graph 相關項目也印證了圖數(shù)據(jù)庫與 AI 結(jié)合是市場和技術共同選擇的結(jié)果。
展望未來
圖數(shù)據(jù)庫的未來發(fā)展方向主要包括三個方面:
擁抱 GQL:繼續(xù)支持和推廣 GQL 標準,,促進圖數(shù)據(jù)庫技術的普及與應用,。
探索基于標準的 HTAP 解決方案:開發(fā)高效的 HTAP 系統(tǒng),滿足日益增長的數(shù)據(jù)處理需求,。
深化圖數(shù)據(jù)庫與 AI 技術的融合:結(jié)合圖數(shù)據(jù)庫和大模型的優(yōu)勢,,推動智能決策支持系統(tǒng)的發(fā)展。
圖數(shù)據(jù)庫不僅在技術上不斷創(chuàng)新,,還在實際應用中展現(xiàn)出巨大的潛力,。未來,圖數(shù)據(jù)庫將在社交網(wǎng)絡,、推薦系統(tǒng),、金融風控等多個領域發(fā)揮重要作用,為數(shù)據(jù)驅(qū)動的決策提供強有力的支持,。
感謝各位的聆聽,,希望今天的分享能夠為大家?guī)硪恍﹩l(fā)和思考。謝謝,。




