首頁>博客>應用場景技術(shù)干貨>如何使用悅數(shù)圖數(shù)據(jù)庫建設(shè)資產(chǎn)管理平臺|眾安科技
如何使用悅數(shù)圖數(shù)據(jù)庫建設(shè)資產(chǎn)管理平臺|眾安科技
本?整理? 悅數(shù)圖數(shù)據(jù)庫 x 阿?云計算巢專場中眾安保險的?數(shù)據(jù)應??級專家曾?帶來的分享,,視頻? 鏈接,。
?家好,我是眾安數(shù)據(jù)科學應?中?的曾?,,今天很?興在這?可以跟?家分享悅數(shù)圖數(shù)據(jù)庫在眾安資產(chǎn)的實踐,。
01 基于事件的數(shù)據(jù)資產(chǎn)平臺設(shè)計
在了解這?切之前,我們需要先知道什么是資產(chǎn)管理平臺以及它可以解決什么樣的問題,。
資產(chǎn)管理平臺是全域的元數(shù)據(jù)中?,,它可以對數(shù)據(jù)資產(chǎn)進行管理監(jiān)控,解決企業(yè)內(nèi)部的數(shù)據(jù)孤島問題,,挖掘數(shù)據(jù)價值并對業(yè)務賦能,。它主要解決我們數(shù)據(jù)找不到、數(shù)據(jù)從哪?取,,排查路徑?,、數(shù)據(jù)復?率低這四個非常核?的關(guān)鍵問題。
設(shè)計目標
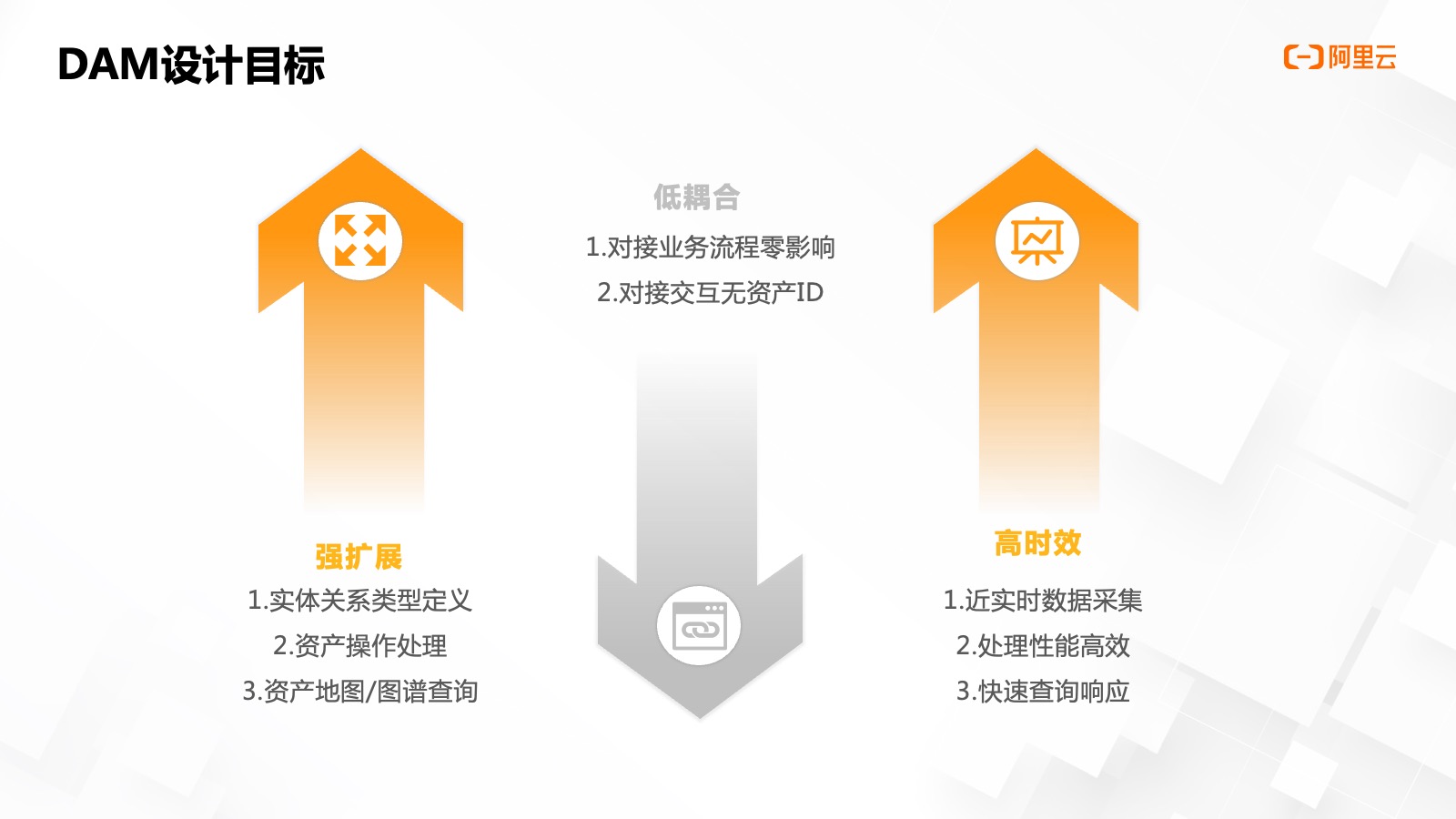
對于資產(chǎn)管理平臺,,我們有三個?常重要的設(shè)計?標——
- 強擴展:是指實體關(guān)系定義,、資產(chǎn)操作以及資產(chǎn)查詢的擴展性。
- 低耦合:是指資產(chǎn)平臺與其他系統(tǒng)對接時,,對接入系統(tǒng)業(yè)務流程零影響,。
- 高時效:是指需要近實時的數(shù)據(jù)采集、快速的數(shù)據(jù)處理和查詢性能,。
核心功能

數(shù)據(jù)資產(chǎn)管理平臺核?功能包括以下三個:
- 類型定義:需提供?個抽象的設(shè)計定義不同的實體/關(guān)系,,以及它們包含的屬性。每個定義的實體/關(guān)系均需要定義唯一性約束,,用于數(shù)據(jù)判重,。在此基礎(chǔ)上我們可以擴展一些定義類型,比如標簽,、術(shù)語,、標簽傳播等等。
- 元數(shù)據(jù)采集:主要有通過周期性,、流式和手工錄入三種方式進行數(shù)據(jù)采集,。
- 元數(shù)據(jù)管理:數(shù)據(jù)存儲常見的選型是關(guān)系型數(shù)庫存儲定義或數(shù)據(jù),,搜索引擎存儲數(shù)據(jù)、變動記錄,、統(tǒng)計類信息,,圖數(shù)據(jù)庫則負責關(guān)系查詢,。數(shù)據(jù)分析常見的場景是數(shù)據(jù)地圖,、血緣及影響性分析、全鏈路血緣分析,。數(shù)據(jù)應用則是在相關(guān)數(shù)據(jù)采集到平臺后,,可以快速實現(xiàn)資產(chǎn)割接、數(shù)據(jù)安全管理以及數(shù)據(jù)治理等更高層次應用需求,。
類型定義
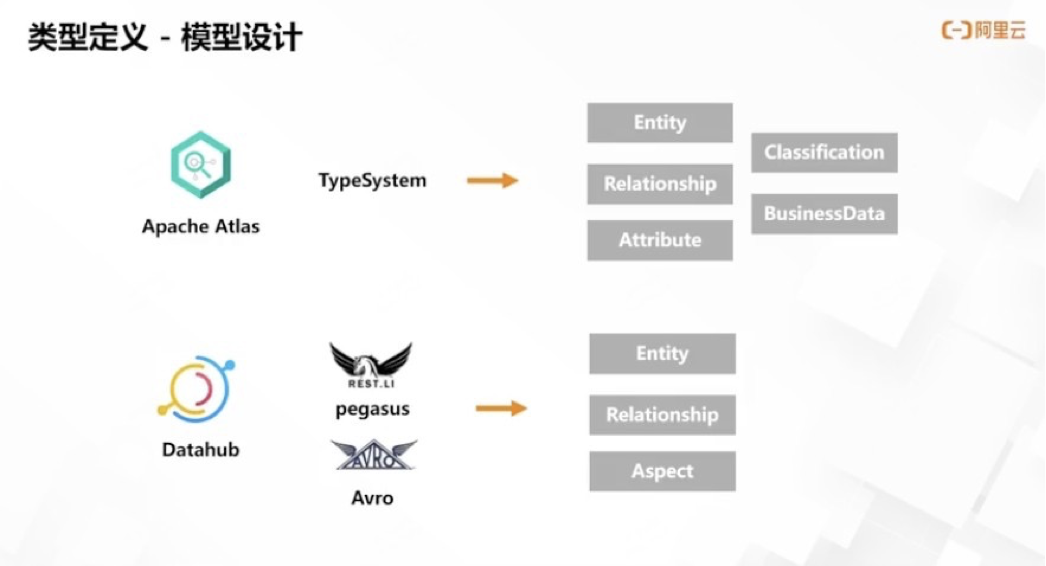
借鑒于開源系統(tǒng) Apache Atlas 和 DataHub,,我們來初步了解類型定義設(shè)計的核心要素。
Atlas 的類型定義模式是一套基于 JSON 的 TypeSystem,,可以自定義擴展,,它的核心概念是實體、關(guān)系和屬性,,并在此基礎(chǔ)上擴展出分類,、術(shù)語、業(yè)務數(shù)據(jù)等定義設(shè)計,。
DataHub 則采用 Avro 進行事件模型的定義,、PEGASUS 建模語言進行實體、關(guān)系和屬性的建模,,值得一提的是 Aspect 這個概念,,其描述實體特定方面的屬性集合,同一實體關(guān)聯(lián)的的多個 Aspect 可以獨立更新,,相同的 Aspect 也可以再多個實體間共享,。DataHub 預置了一些實體和關(guān)系模型,我們可以復用這些模式或自定義新模型,。
通過兩個開源系統(tǒng)的類型定義設(shè)計,,我們不難看出實體、關(guān)系,、屬性是元數(shù)據(jù)系統(tǒng)當中最基礎(chǔ)的三個核心類型定義的元素,。基于整體的架構(gòu),、內(nèi)部數(shù)據(jù)模型場景,、數(shù)據(jù)存儲選型、學習成本等方面因素的考慮,,眾安數(shù)據(jù)資產(chǎn)平臺的類型定義是參照 Apache Atlas 的 TypeSystem 設(shè)計,,定義一套獨立的類型定義系統(tǒng),。
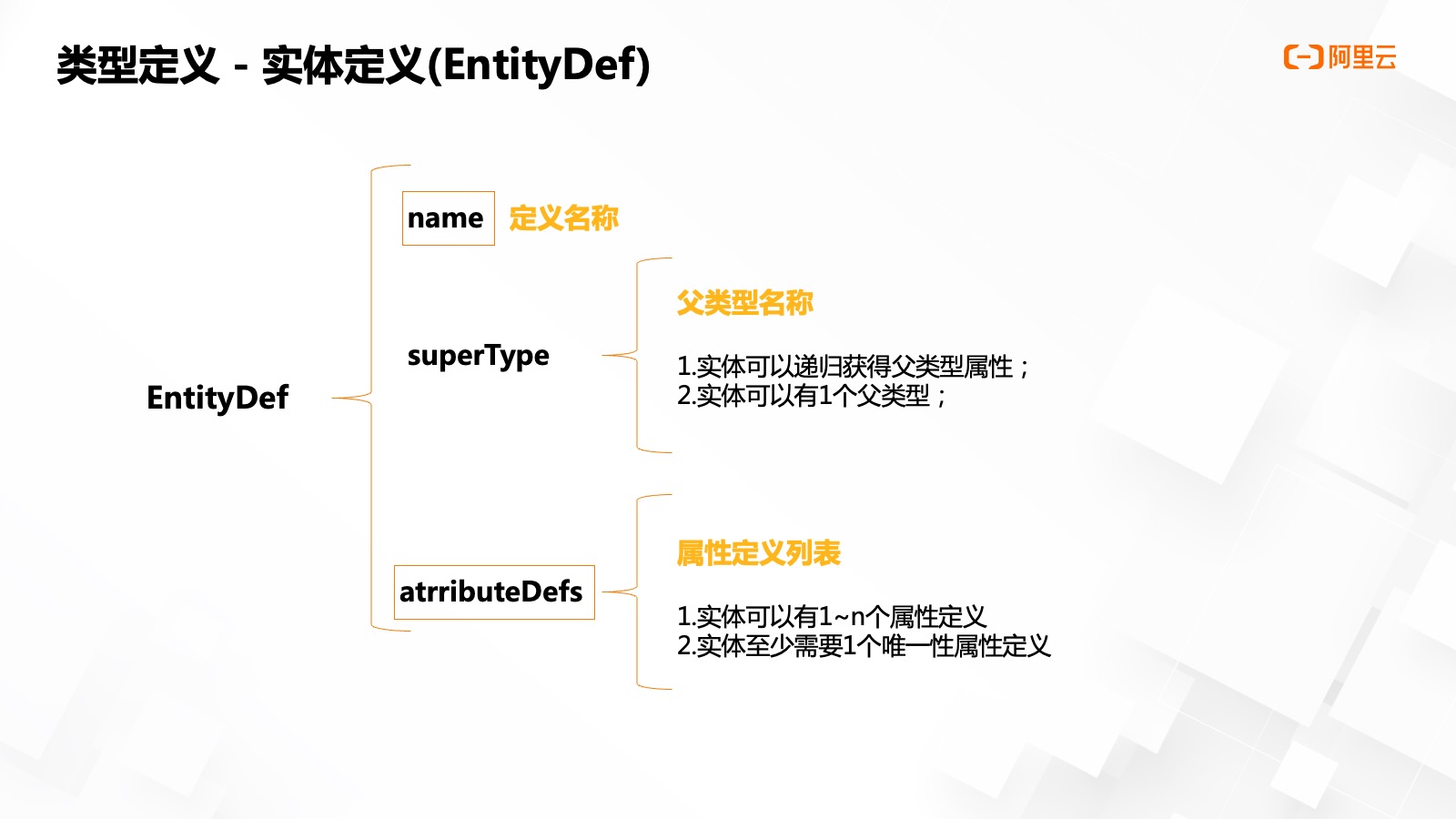
實體類型定義 EntityDef 的核心要素是類型名稱、父類型名稱和屬性列表,。
對于類型名稱,,需要單租戶下約束唯一;對于父類型名稱,,其實就是對一些公共屬性集的復用,,類似于 Java 類的繼承機制,我們可以通過獲取父類型及其超類的所有屬性,。目前為方便類型解析,,一個實體僅能定義一個父類型。對于屬性列表,,一個實體可以有 1~n 個屬性,,且至少有一個唯一性屬性。

關(guān)系定義 RelationshipDef 的核心要素是定義名稱,、關(guān)系類別,、起始/結(jié)束端點定義和屬性定義;
對于類型名稱,,需要單租戶下約束唯一,;對于關(guān)系類別,根據(jù)是否容器關(guān)系和端點實體生命周期分為三類,。
- Association 關(guān)系:是一種非容器關(guān)系,,比較典型的例子是調(diào)度作業(yè)的依賴關(guān)系,兩者之間不為包含關(guān)系,,且生命周期獨立,。
- Aggregation 關(guān)系:是一種容器關(guān)系,但端點實體的生命周期獨立,,比如我們的報表系統(tǒng),,數(shù)據(jù)模型和畫布關(guān)系,畫布包含模型,,但模型可以獨立于畫布而出存在,,生命周期獨立。
- Composition 關(guān)系:是一種容器關(guān)系,,且端點生命周期完全一致,,最直觀的例子是表和列之間的包含關(guān)系,刪除表的時候列實體自動被刪除,。
對于端點定義 RelationshipEndDef,,端點即是實體關(guān)系中關(guān)系實體的映射,所以需要定義來源和目標兩個端點,。每個端點定義需要端點的實體類型名稱以及是否為容器,。如果關(guān)系類別是?個容器類型的關(guān)系的話,,需要設(shè)置某?個端點容器標志為 true,此時邊方向是子項實體指向容器實體,。如果關(guān)系類別是非容器的關(guān)系的話,,所有的端點容器標志都需要設(shè)置為 false,此時邊方向是端點 1 實體指向端點 2 實體,。
對于屬性列表來,,一個關(guān)系可以有 0~n 個屬性。同實體屬性定義不同的是,,關(guān)系定義可以不配置屬性定義,。

屬性定義 AttributeDef 核心要素是名稱,、類型,、是否可選、是否唯一屬性,、是否創(chuàng)建索引,、默認值等內(nèi)容。對于屬性類型,,因 NebulaGraph 圖庫支持的類型有限,,僅支持基礎(chǔ)數(shù)據(jù)類型。是否支持索引創(chuàng)建,,是指創(chuàng) Nebula tag/edge schema 的時候,,對于某個屬性是否創(chuàng)建一個 tag/edge 索引,以支持在特殊查詢場景下的數(shù)據(jù)查詢,。
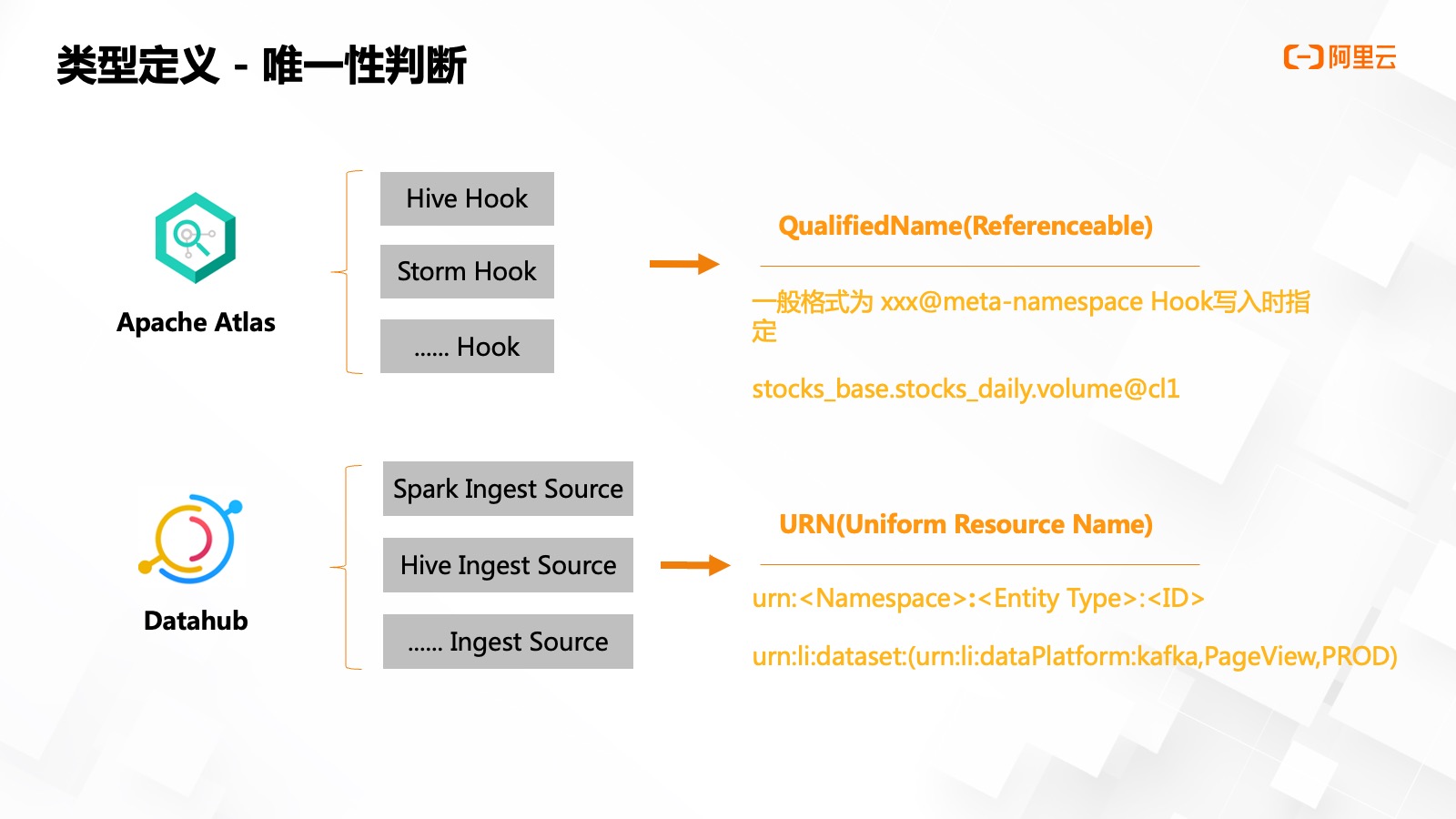
實體的判重是資產(chǎn)平臺類型定義的關(guān)鍵設(shè)計,,我們首先看看開源產(chǎn)品的設(shè)計理念。
Atlas 類型定義系統(tǒng)當中,,所有實體都繼承于?個?實體 Referenceable,,它只有?個唯一屬性 QualifiedName,且被標記為了唯?的屬性,。所有繼承于它的實體類型屬性中均沒有唯一屬性,。QualifiedName 沒有用固定格式,在 Atlas 內(nèi)置的幾個 Hook 中,,主要格式為 xxx@meta-namespace,。在 Hook 寫入時指定,上圖的例子就定義的是某個集群,、某個存儲卷在的唯一性標識,。
DataHub 實體唯一性標志是 URN,也叫作唯?屬性資源名稱,。它有一定的生成規(guī)則,,即 urn:<namspace>:<Entity Type>:<ID> 命名空間默認設(shè)置為 li,,類別則是實體定義名稱,ID 是指唯一屬性集合拼接,,可以嵌套 URN,,上圖的例子一個數(shù)據(jù)集,代表某個 Kafka 集群下的 Topic,。
基于兩個開源項目分析,,不難看出唯一性判斷均是基于唯一屬性來處理,兩者均是在 Ingest 擴展中進行了固定格式的定義寫入,,而不是基于實體定義中多個明確代表唯一屬性進行靈活的拼接處理,,其拼接的字段晦澀難以解析。

眾安設(shè)計了一套唯一性判斷定義方式,,即某個實體注冊時,,先判斷實體定義是否有 Composition 類別關(guān)系的邊定義引用。如果不存在該關(guān)系類別定義,,則直接從實體定義的屬性定義中檢索 isUnique=true 的屬性,。如果存在改關(guān)系類別定義,那當前實體的唯一性屬性將不足以約束其唯一性,,還需要帶上邊定義的容器實體的唯一屬性才可以保證,。這是一個遞歸的過程,可能需要傳入多個實體的唯一性屬性才可以判斷,。比如注冊一個 MySQL 表,,除了表實體的表名稱之外,還需要 MySQL 庫實體的 Host,、端口,、數(shù)據(jù)庫名稱等唯一屬性才是完整的為唯一屬性列表。
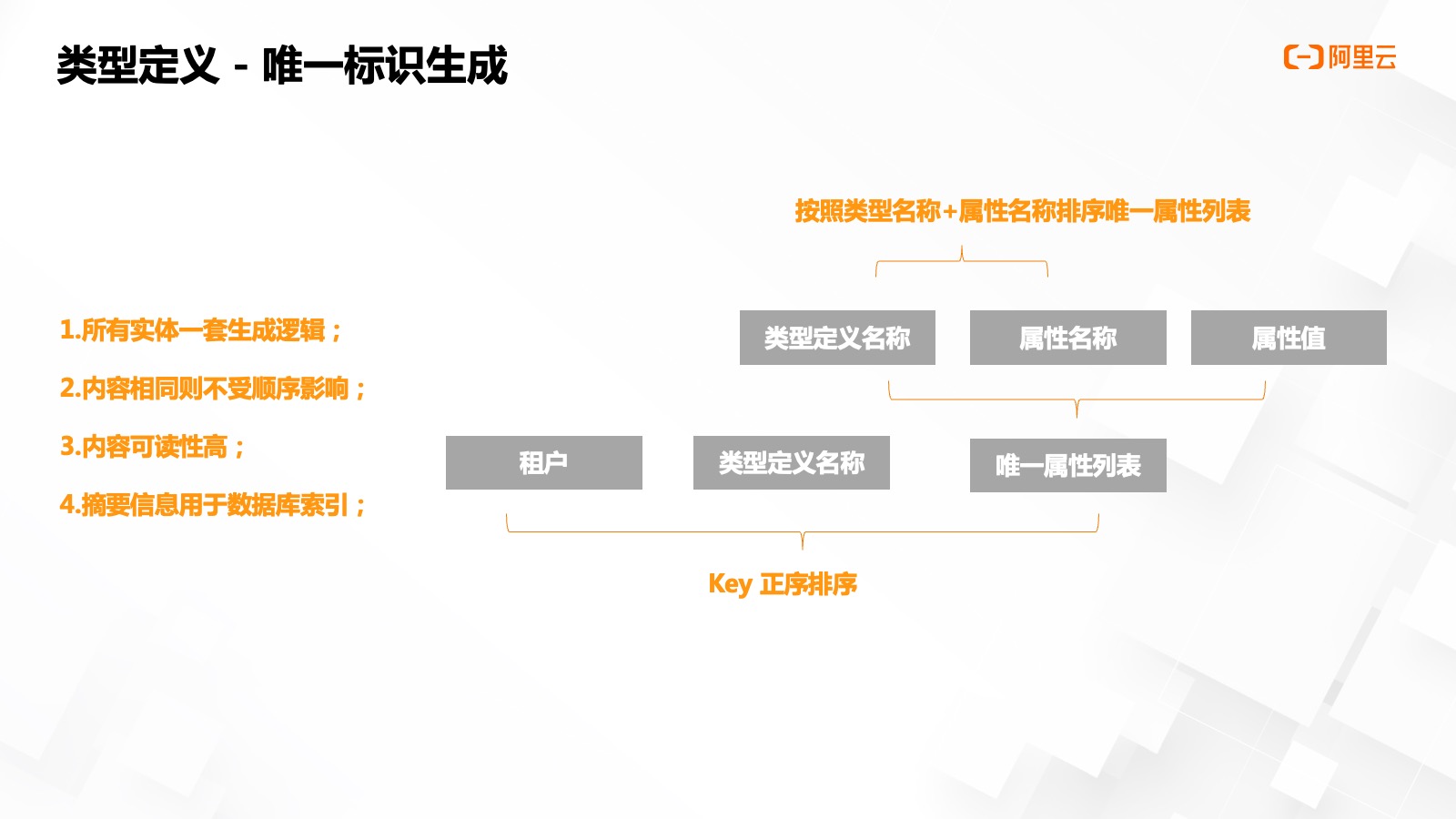
在獲取了唯一屬性列表后,,還需要加上租戶和類型定義名稱,,繼而生成某一租戶下對應的唯一實體標志。
操作需要三個流程,,首先需要把唯?性的屬性列表,,根據(jù)其對應的類型名稱跟屬性名稱進行一次正序排序,然后對租戶,、類型定義名稱,、唯一屬性 key 進行一次正序排序,生成一個可讀性高的唯一名稱,。其次,,因唯一名稱可能較長,需要進行一次 32 位摘要后進行存儲,并加以索引進行查詢,,可以提升整體查詢的有效性,。最終全局的資產(chǎn)唯一 ID,則是用 Snowflake 算法生成的唯一 ID,。因摘要算法有效概率重復,,故使用分布式 ID 生成算法生成 ID,用于數(shù)據(jù)存儲,。
資產(chǎn)采集
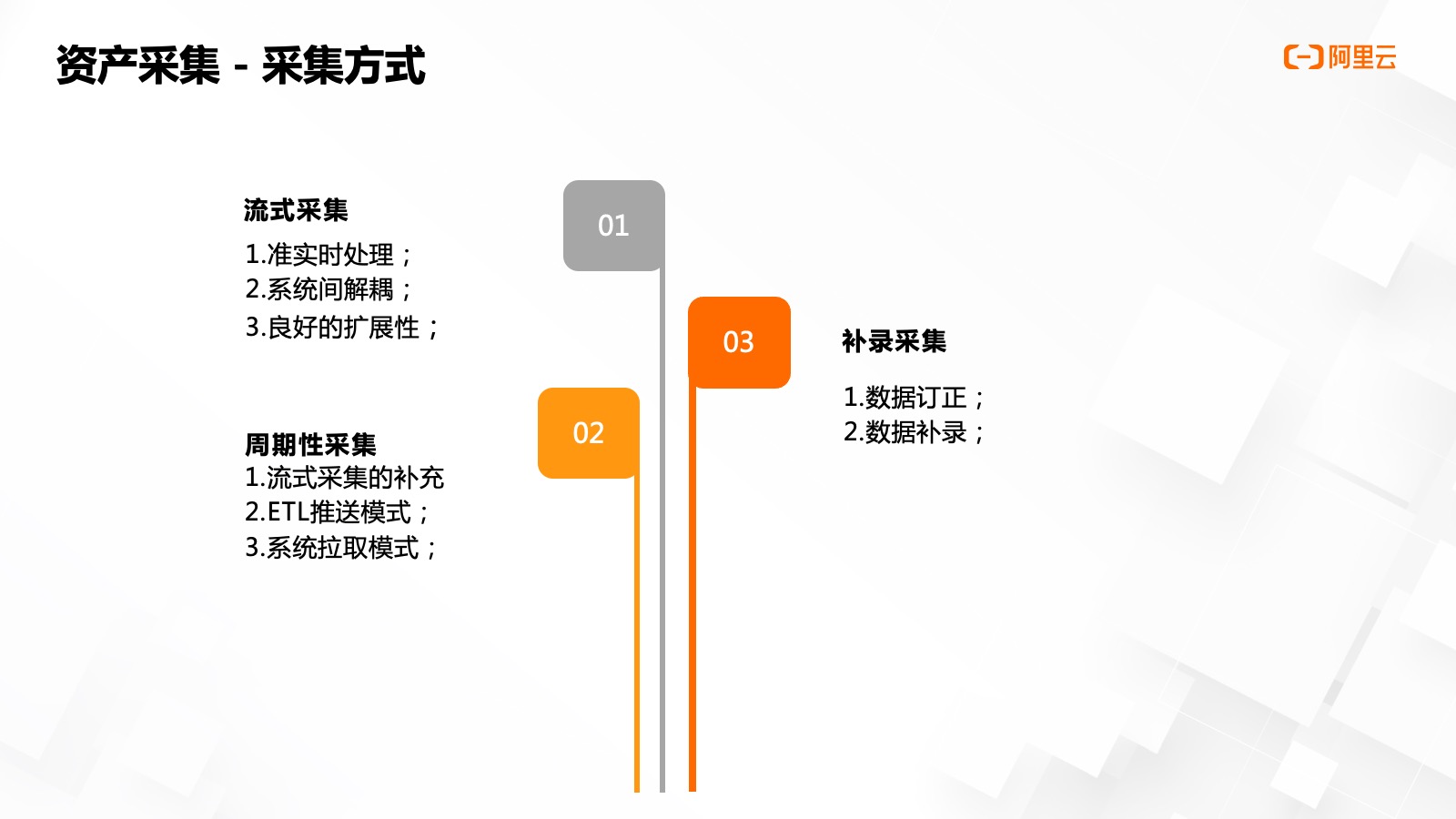
流式采集有非常好的優(yōu)勢,,可以通過消息隊列,實現(xiàn)系統(tǒng)間解耦,,實現(xiàn)數(shù)據(jù)的準實時上報,,同時對事件消息也有良好的擴展性。周期性采集是流式采集的?個補充,,它包括兩種?式基于 ETL 或系統(tǒng)接口的主動推送,,或類似數(shù)據(jù)發(fā)現(xiàn)系統(tǒng)的數(shù)據(jù)主動拉取。
對于以上兩種?式還沒有達成的采集,,可以用過人工補錄的形式進行填寫,,以支持注入對接系統(tǒng)無法支持上報或部分血緣無法解析等場景,,提升數(shù)據(jù)完整度,。
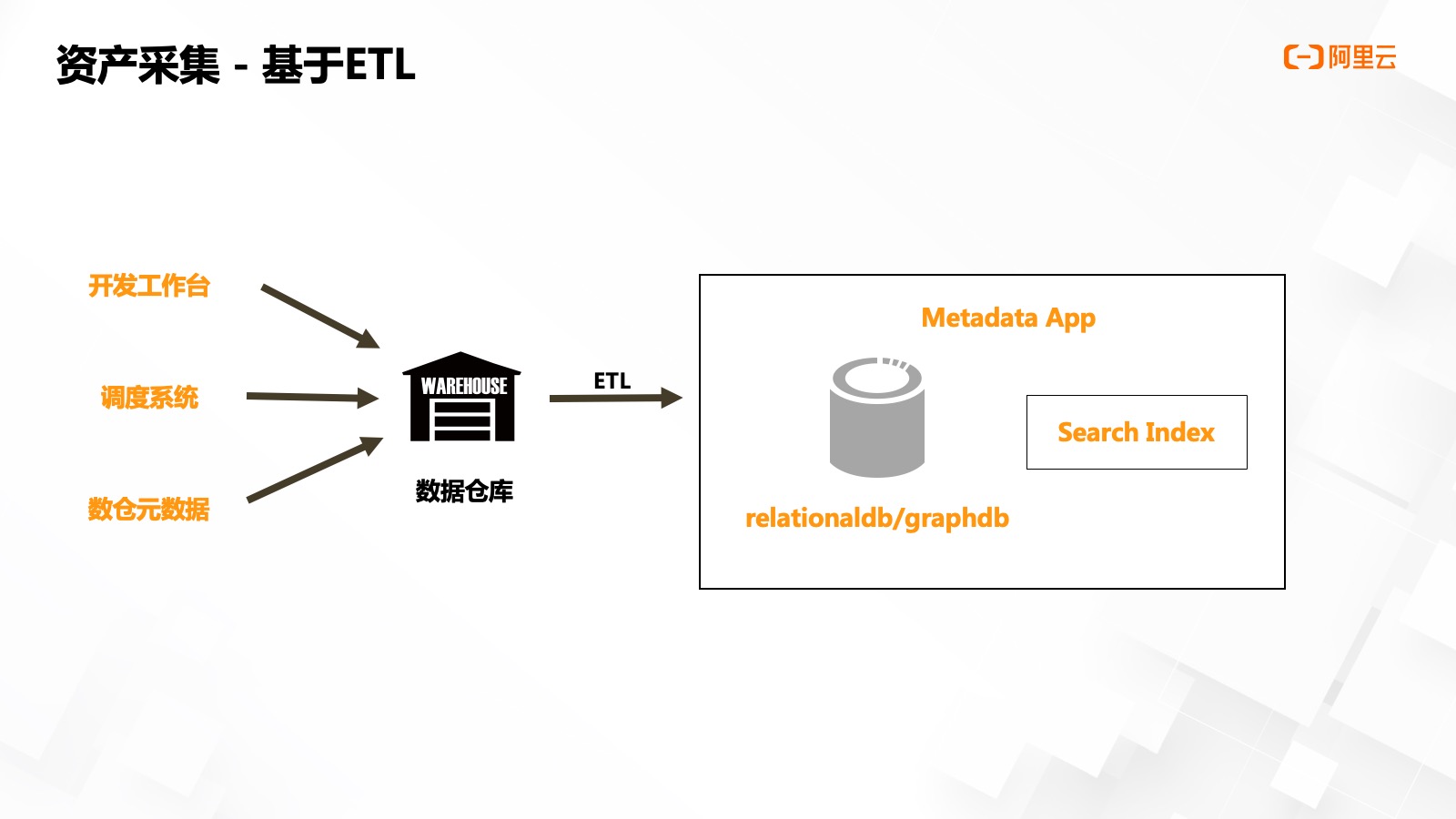
下面給大家介紹一下眾安元數(shù)據(jù)系統(tǒng)?個版本采集流程的迭代——
V1.0 版本是完全基于 T+1 的離線 ETL,我們會把數(shù)據(jù)開發(fā)?作臺,、調(diào)度系統(tǒng)以及阿?云 MaxCompute 元數(shù)據(jù)加載到數(shù)倉后,,通過 ETL 處理推送到元數(shù)據(jù)平臺,因數(shù)據(jù)量不大一個支持遞歸的關(guān)系型數(shù)據(jù)庫即可滿足要求,。若數(shù)據(jù)量較大,,則可以通過搜索引擎和圖數(shù)據(jù)庫進行擴展。

隨著業(yè)務的發(fā)展,,數(shù)據(jù)開發(fā)對于元數(shù)據(jù)的時效性要求會越來越高,,比如分析師創(chuàng)建的臨時數(shù)據(jù)想 T0 就直接分享給其他部門使用,以及元數(shù)據(jù)整體數(shù)量越來越大,,處理耗時較長,,獲取的時間越來越晚。
基于以上需求,,我們在元數(shù)據(jù)平臺開了?層 API,,在數(shù)據(jù)開發(fā)工作臺進行表操作時,或調(diào)度系統(tǒng)創(chuàng)建調(diào)度任務時,,會調(diào)用接口將數(shù)據(jù)同步給元數(shù)據(jù)平臺,。同時晚上我們依然會有離線的 ETL 進行數(shù)據(jù)補充,兩者結(jié)合起來進行數(shù)據(jù)源的數(shù)據(jù)查詢服務,。
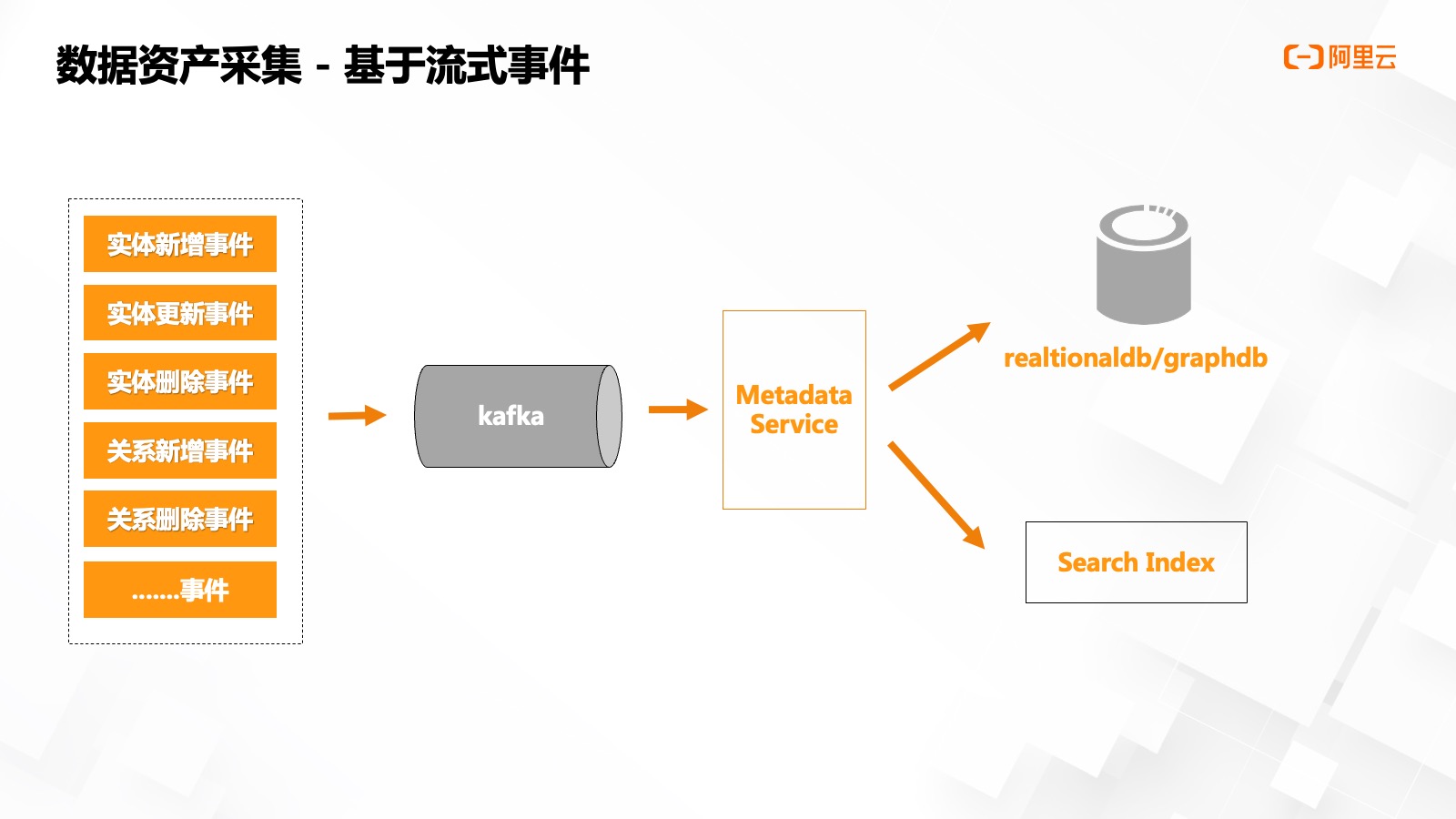
接口模式也會有一定的弊端,,在各個對接的業(yè)務系統(tǒng)中,,會有大量的同步嵌套流程,元數(shù)據(jù)服務不可用或執(zhí)行時間過長,,例如系統(tǒng)發(fā)版時的業(yè)務中斷,,創(chuàng)建一個數(shù)百列的表引發(fā)的接口超時等,均會影響正常業(yè)務流程,。
于是我們參考各類開源元數(shù)據(jù)平臺設(shè)計思路,,設(shè)計了基于流式事件的元數(shù)據(jù)平臺,基于不同的事件,,對接系統(tǒng)通過消息隊列上報后,,實現(xiàn)系統(tǒng)間解耦。資產(chǎn)平臺基于不同事件進行分類處理,,并將最終的數(shù)據(jù)存儲到搜索引擎,、關(guān)系型數(shù)據(jù)庫,以及圖數(shù)據(jù)庫當中,。
平臺架構(gòu)
下?給?家介紹?下眾安數(shù)據(jù)資產(chǎn)平臺的架構(gòu),,我們將平臺分為了 5 個子系統(tǒng)。
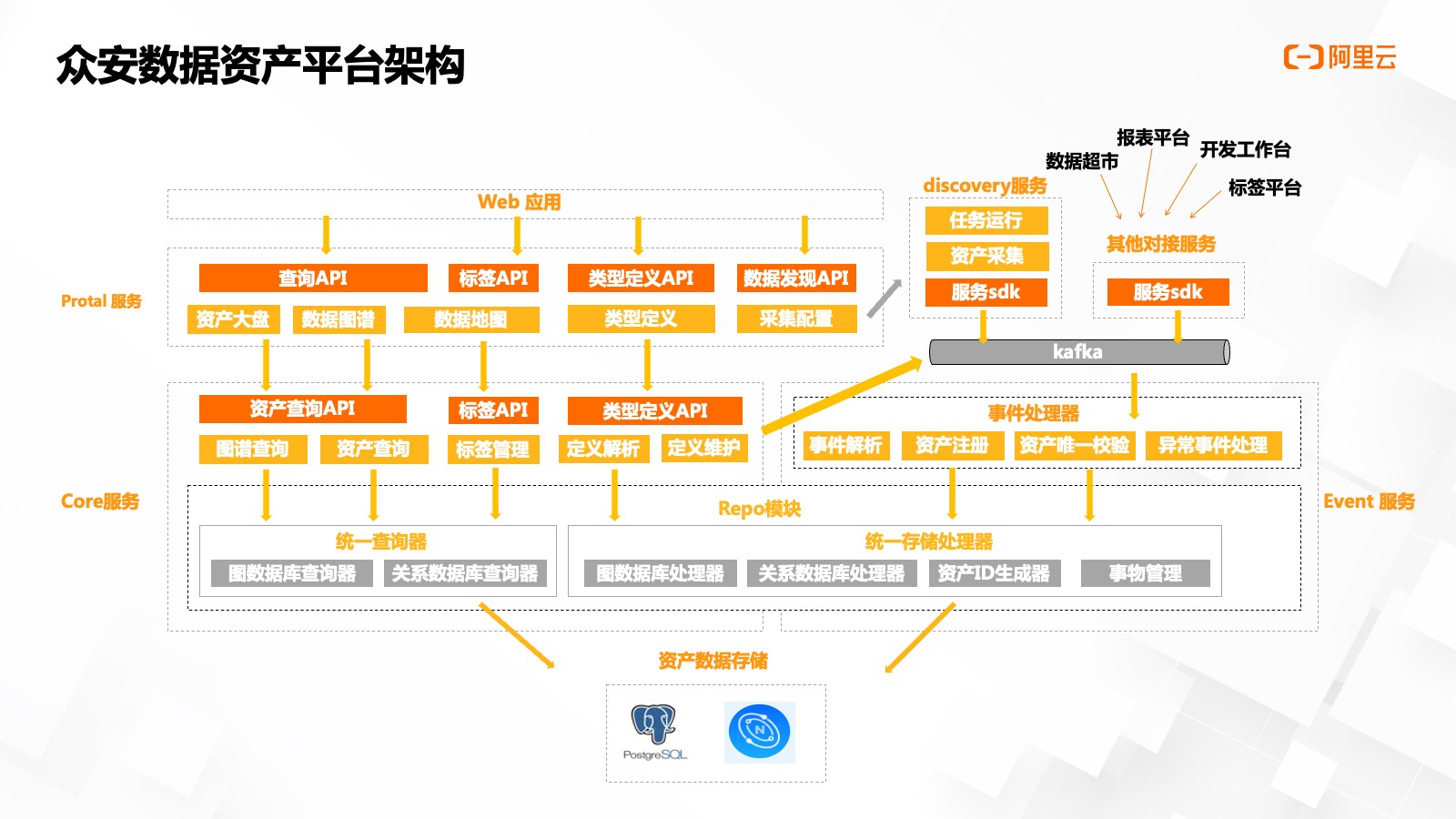
- Portal 服務對接前端,,提供通用的實體頁面布局配置接口,,實現(xiàn)配置化的頁面布局。同時轉(zhuǎn)發(fā)請求到 Core Service 進行處理,,比如查詢,、類型定義等。
- Discovery 服務主要就是周期性的采集服務,,通過配置定時的采集任務,,并實現(xiàn)元數(shù)據(jù)的定時采集。
- 系統(tǒng) SDK 所有服務對接資產(chǎn)平臺,,均需要通過 SDK 進行對接,,包括 Discovery 服務、數(shù)據(jù)超市,、報表平臺,、開發(fā)?作臺、數(shù)據(jù)標簽平臺等,,SDK 提供了統(tǒng)一的事件拼裝,、權(quán)限管理、事件推送等功能,,可以極大的提升平臺間交互的開發(fā)效率,。
- Event 服務負責消費消息隊列中的消息,進行事件的解析和數(shù)據(jù)持久化。
- Core 服務提供統(tǒng)一的查詢 API,、標簽 API 以及類型定義的 API 來實現(xiàn)查詢跟類型定義的管理,。
同時我們提供了統(tǒng)一的數(shù)據(jù)存儲層模塊 Repo,來實現(xiàn)查詢器和統(tǒng)一數(shù)據(jù)處理器的相關(guān)處理,,其內(nèi)部提供了數(shù)據(jù)庫及圖庫的擴展 SPI,,以便實現(xiàn)相關(guān)擴展。
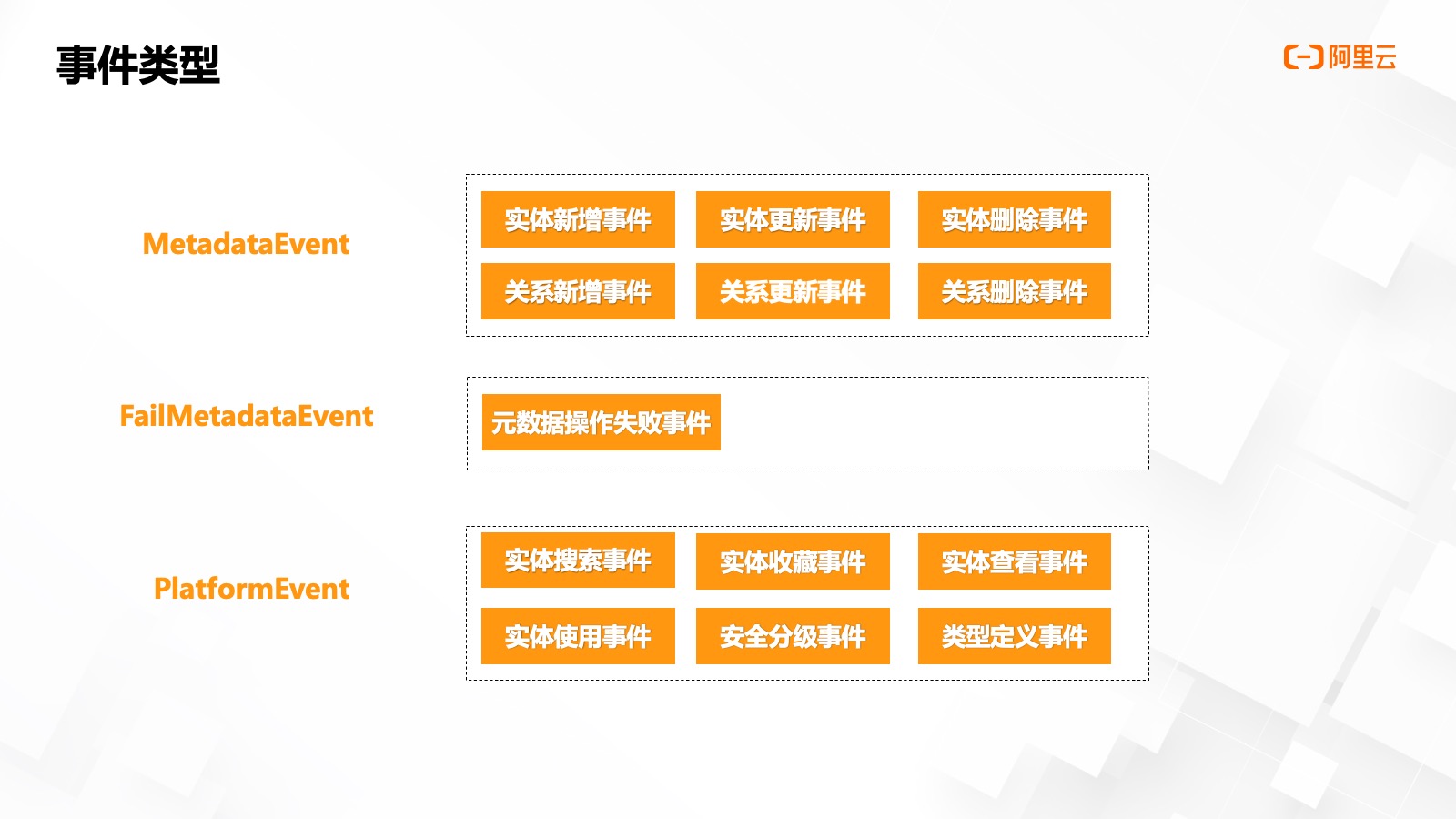
我們將資產(chǎn)平臺的事件抽象為以下三種:
- 元數(shù)據(jù)事件 MetadataEvent,,包括實體/關(guān)系的增刪改查等子事件,。
- 元數(shù)據(jù)異常事件 FailMetadataEvent,在處理 MetadataEvent 時失敗了,,比如類型定義不存在或事件順序有問題,,我們會統(tǒng)一生成一個元數(shù)據(jù)異常失敗事件,可以基于此事件做異常數(shù)據(jù)落庫或告警通知,。
- 平臺事件 PlatformEvent,,包括使用元數(shù)據(jù)平臺觸發(fā)的埋點事件,包括實體的收藏,、查詢,、使用以及安全分級等事件,其中一部分會做按天級別的統(tǒng)計處理,,以便在平臺上可以看到類似的統(tǒng)計信息,。
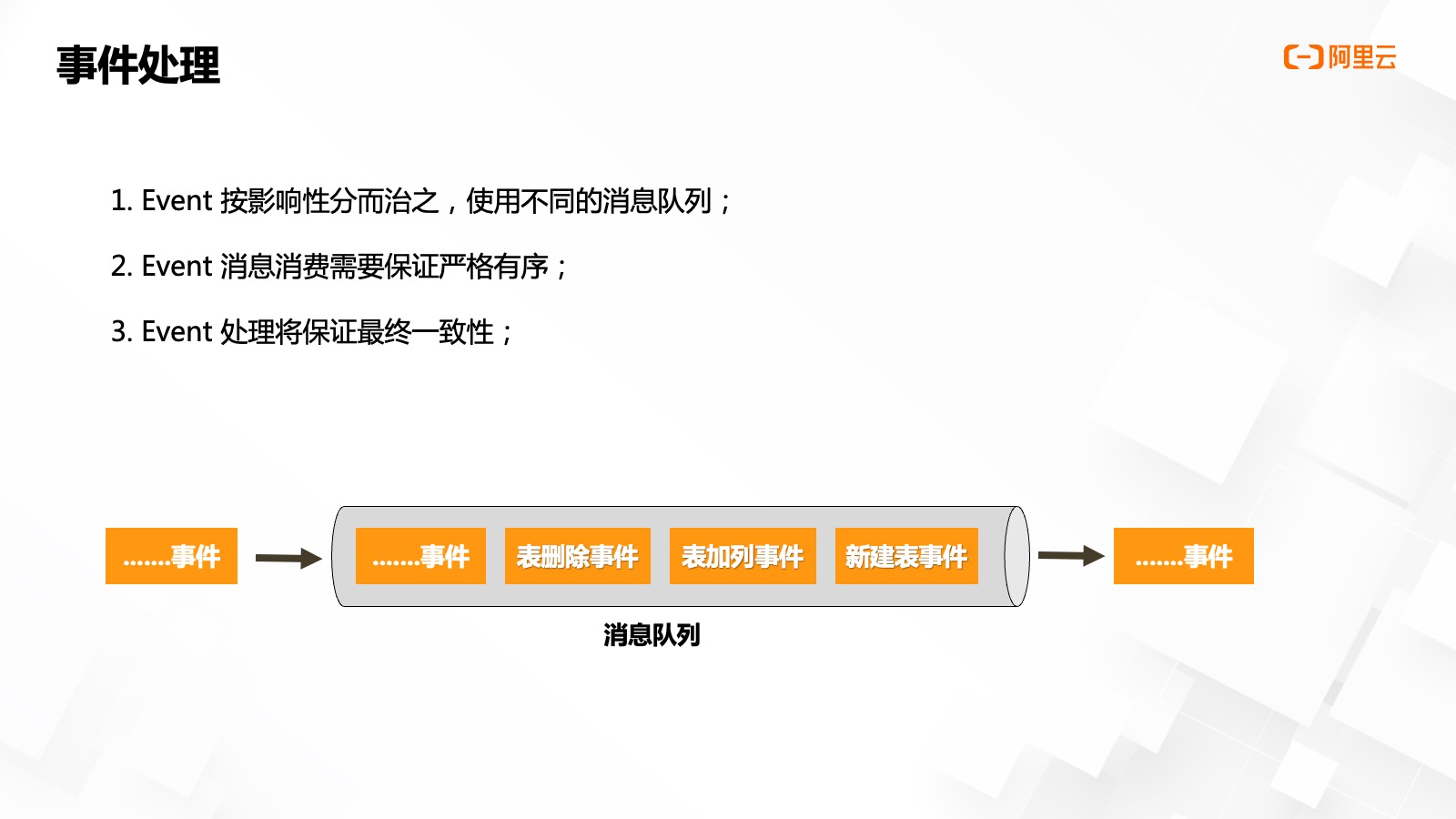
事件進?處理,需要關(guān)注以下三點:
- 分而治之,,因為整體的事件的數(shù)據(jù)量會?較多,,為了保證性能需要按照 Event 類別和影響,使?不同的消息隊列,。對于我們剛才介紹的三種型的事件,我們實際使用了三個 Kafka Topic 進行消息推送,。
- 消息的順序,,對于元數(shù)據(jù)相關(guān)事件,消息消費需要嚴格保證有序,,如何來保證有序呢,?我們?前采?的?案是由 Kafka Topic 單分區(qū)模式來解決的,為什么不?多 Partition 呢,?因為實體跟關(guān)系之間的注冊有可能是會分到不同的 Partition 上來進?處理的,,因為異步消費處理有可能不同分區(qū)的數(shù)據(jù)產(chǎn)生消費堆積,有概率出現(xiàn)不同的分區(qū),,消費注冊事件先到,,實體注冊事件后到的情況,導致廢消息的出現(xiàn)。
- 最終一致性,,因為事件 Event 的異步處理,,我們只能保證數(shù)據(jù)的最終?致性。

好,,那講完了事件的消費流程,,我們下?就要來看數(shù)據(jù)持久化的流程。我們的數(shù)據(jù)事件從消息隊列拿到之后,,會被我們的事件服務 Event Service 所消費,,Event Service 中的事件處理器在消費數(shù)據(jù)的時候會?刻對這個數(shù)據(jù)進??份數(shù)據(jù)的存儲,它會存到關(guān)系型數(shù)據(jù)庫??,,作為?個審計的回溯?志,。
在存儲完回復?志之后,事件處理器就會開始對事件進?處理,,如果事件處理異常的話,,根據(jù)特定的這種事件類型,我們會有選擇的把?些異常的事件放到異常事件的消息隊列??,,然后供下游的系統(tǒng)進?訂閱通知,,或者是做內(nèi)部后期的問題排查。
如果事件處理成功了之后,,我們會把數(shù)據(jù)丟到聯(lián)合數(shù)據(jù)處理器當中,。那聯(lián)合數(shù)據(jù)處理器內(nèi)部其實就是我們對關(guān)系型數(shù)據(jù)庫以及圖庫的數(shù)據(jù)進?了?個整體的事務的包裹,以便兩者之間出現(xiàn)失敗的時候,,可以對數(shù)據(jù)內(nèi)容進?回滾,。
那在數(shù)據(jù)持久化當中,我們的關(guān)系型數(shù)據(jù)庫跟圖庫當中分別存儲了什么內(nèi)容呢,?像關(guān)系型數(shù)據(jù)庫當中,,我們往往存儲了實體跟關(guān)系的數(shù)據(jù),包括屬性跟這種實際的這種名稱的?些定義,,同時還存儲了實體的統(tǒng)計類的信息?于分析,,還有類型定義的數(shù)據(jù)?于各種各樣數(shù)據(jù)的這樣?種校驗。那圖庫當中主要就是點邊的這種關(guān)系?于圖譜的查詢,。
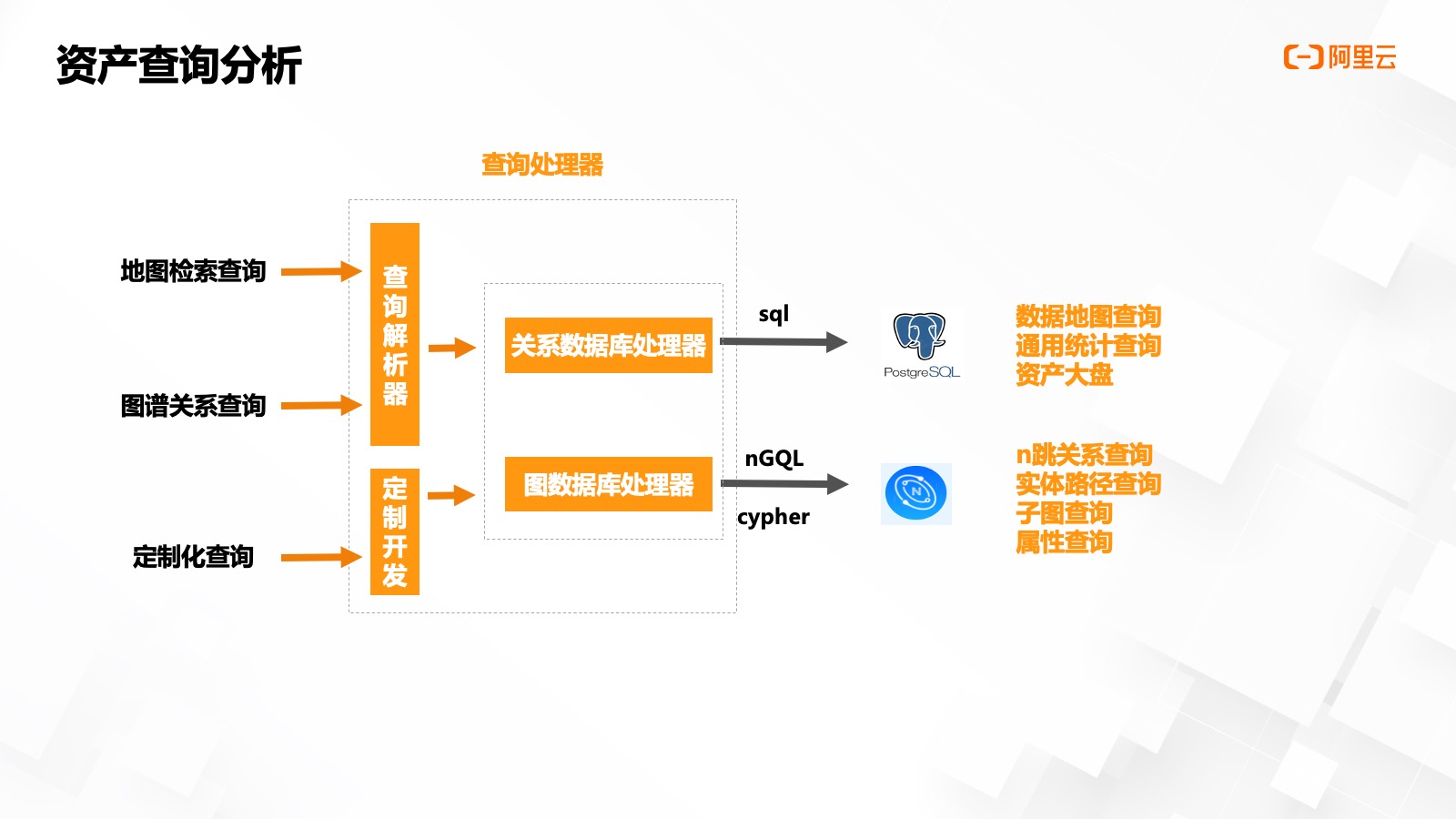
資產(chǎn)的查詢分析集成于 Core Service 模塊中,,目前有兩大場景分類,數(shù)據(jù)地圖和血緣分析,。
數(shù)據(jù)地圖類檢索,,一般是分查詢,我們定義一套類似于 ES DSL 風格的查詢接口請求,,通過查詢解析器,,翻譯成要查詢的關(guān)系型數(shù)據(jù)庫語句,,目前因為數(shù)據(jù)量還在 PG 的承受范圍內(nèi),我們并沒有使用 ES,。同時使用,、收藏、查詢的統(tǒng)計類記錄和變動記錄,,也是存放于 PG 當中,,通過指定接口查詢。
血緣分析類查詢,,一般是關(guān)系查詢,,我們也通過類似于 ES DSL 風格的查詢接口請求,通過查詢解析器,,翻譯成圖數(shù)據(jù)庫所識別的 nGQL 或 Cypher 語句,,包括 N 跳關(guān)系查詢、子圖查詢,、屬性查詢等,。
對于?些特殊場景查詢需求,比如數(shù)據(jù)大盤,,或特定實體的擴展事件,,我們通過或定制化查詢的方式進行處理。
02 悅數(shù)圖數(shù)據(jù)庫在眾安資產(chǎn)平臺的實踐
圖數(shù)據(jù)庫選型
我們在做?主化平臺開發(fā)之前,,對熱門開源項目的圖數(shù)據(jù)庫選型做了調(diào)研,。
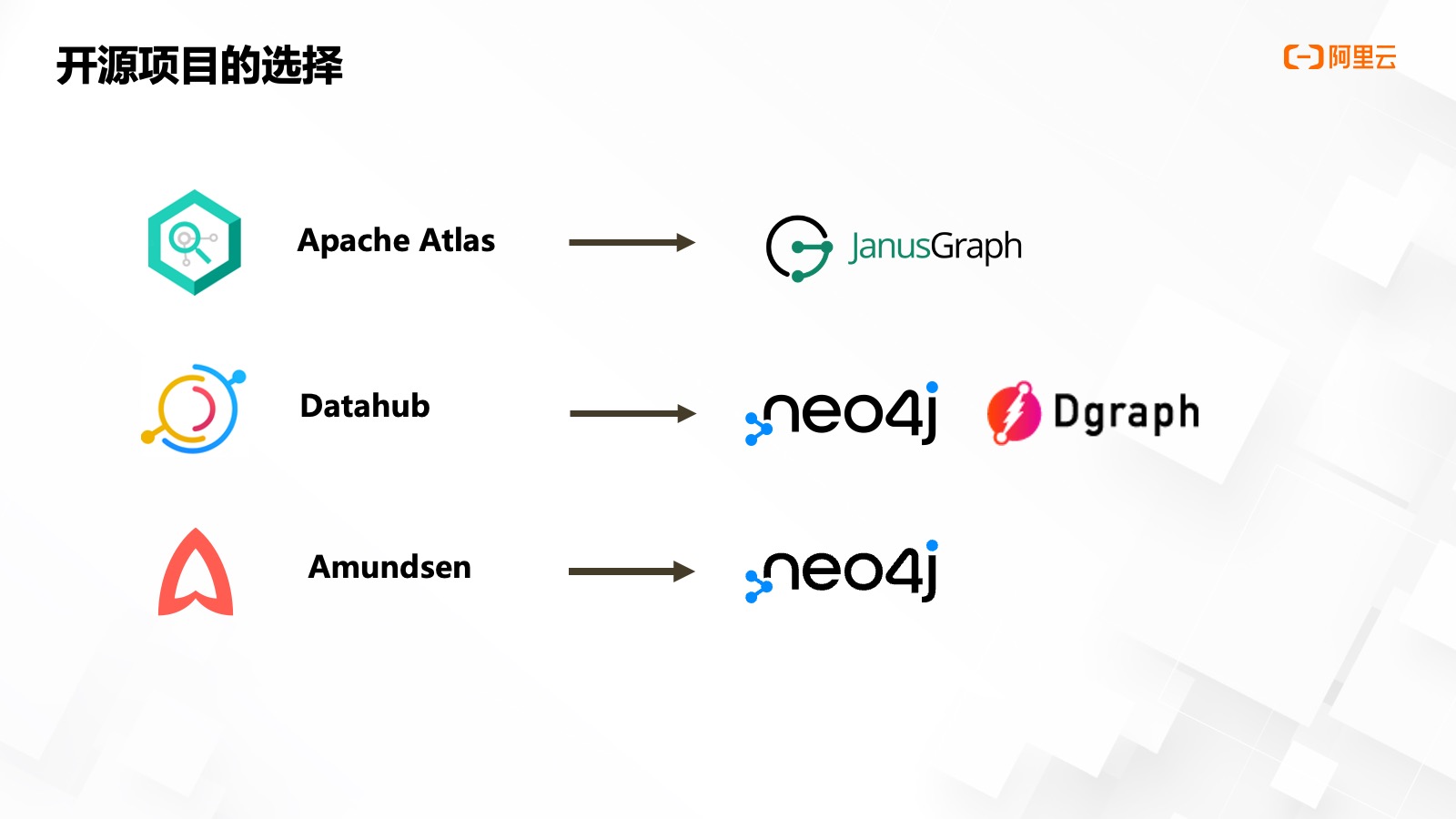
選型主要考慮兩??的因素,數(shù)據(jù)庫架構(gòu)和資產(chǎn)平臺設(shè)計的匹配性,。
在架構(gòu)因素??,,核心因素是讀寫性能、分布式擴展,、事務支持和第三方依賴,。對于 Neo4j 來說,雖然它的性能讀寫性能?常優(yōu)越和原?存儲,,但是因為 3.x 版本之后,,社區(qū)版已經(jīng)不再?持分布式模式,所以說肯定不能達到我們預期的要求,。JanusGraph 和悅數(shù)圖數(shù)據(jù)庫均支持分布式擴展和存算分離架構(gòu),但前者的存儲,、索引均依賴于第三方組件,,帶來大量額外運維工作。

資產(chǎn)平臺設(shè)計的匹配性因素,,核心因素是數(shù)據(jù)隔離,、屬性及 Schema 數(shù)量上線,、屬性類型、查詢語言等,。
JanusGraph/Neo4j 社區(qū)版屬性集均不支持強 Schema,,這意味著更靈活的屬性配置。同時,,屬性類型也支持諸如 map,、set 等復雜類型。悅數(shù)圖數(shù)據(jù)庫屬性集雖然有強 Schema 依賴,,但屬性和 Schema 數(shù)量沒有上限,,也支持 Schema 的修改,唯一美中不足的是不支持 map/set 等復雜類型屬性,,這將對類型定義和系統(tǒng)設(shè)計有一定的影響,,以及對潛在的需求場景有一定的約束。三種數(shù)據(jù)庫均有通用的查詢語言,、以及可以基于 GraphX 進行圖算法分析,。
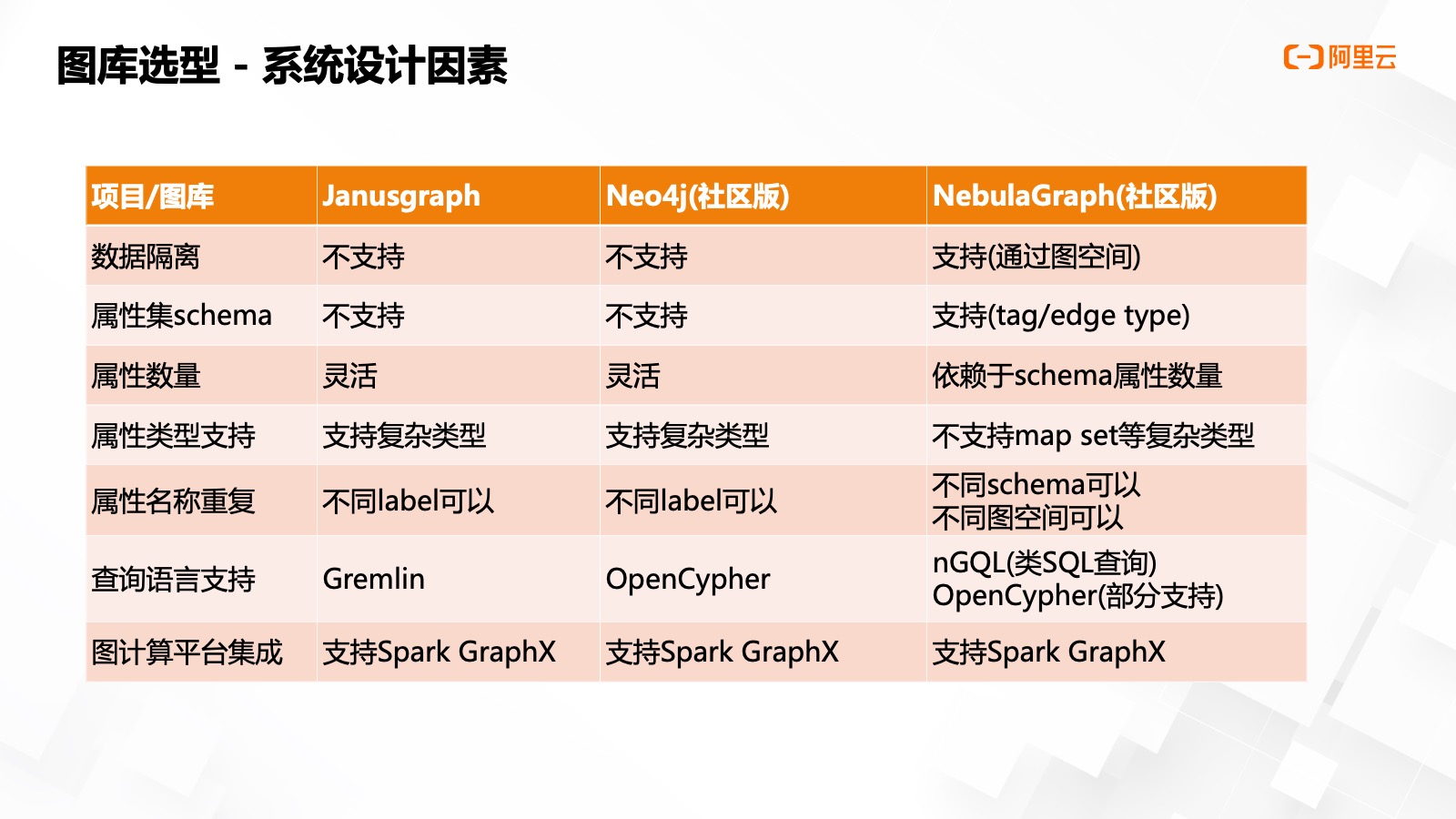
為什么選擇 NebulaGraph
基于以下四點的考慮,眾安選擇了悅數(shù)圖數(shù)據(jù)庫——
第?是分布式的存算分離架構(gòu),,可以以最優(yōu)的成本,,快速擴縮容相關(guān)服務。
第二是外部組件依賴較少,,?便運維,。
第三是卓越的讀寫性能,在19 年年底眾安金融風控場景,,我們對 NebulaGraph 就進?了?定的性能測試,,我們在純 nGQL的 insert 這種寫入方案下,通過 DataX 可以實現(xiàn) 300w record/s 的數(shù)據(jù)寫?速度,,這個是一個非常驚人的數(shù)據(jù)同步的體驗,。
第四是數(shù)據(jù)存儲格式,因為眾安有大量的子公司租戶,,需要進行數(shù)據(jù)的存儲隔離,,如果是其他產(chǎn)品就需要部署多套圖庫,或一套圖庫數(shù)據(jù)里打租戶標簽,。悅數(shù)圖數(shù)據(jù)庫可以使用圖空間的方式實現(xiàn)天然的數(shù)據(jù)隔離,,大大簡化了我們開發(fā)的工作量。
悅數(shù)圖數(shù)據(jù)庫 x 阿?云部署模式
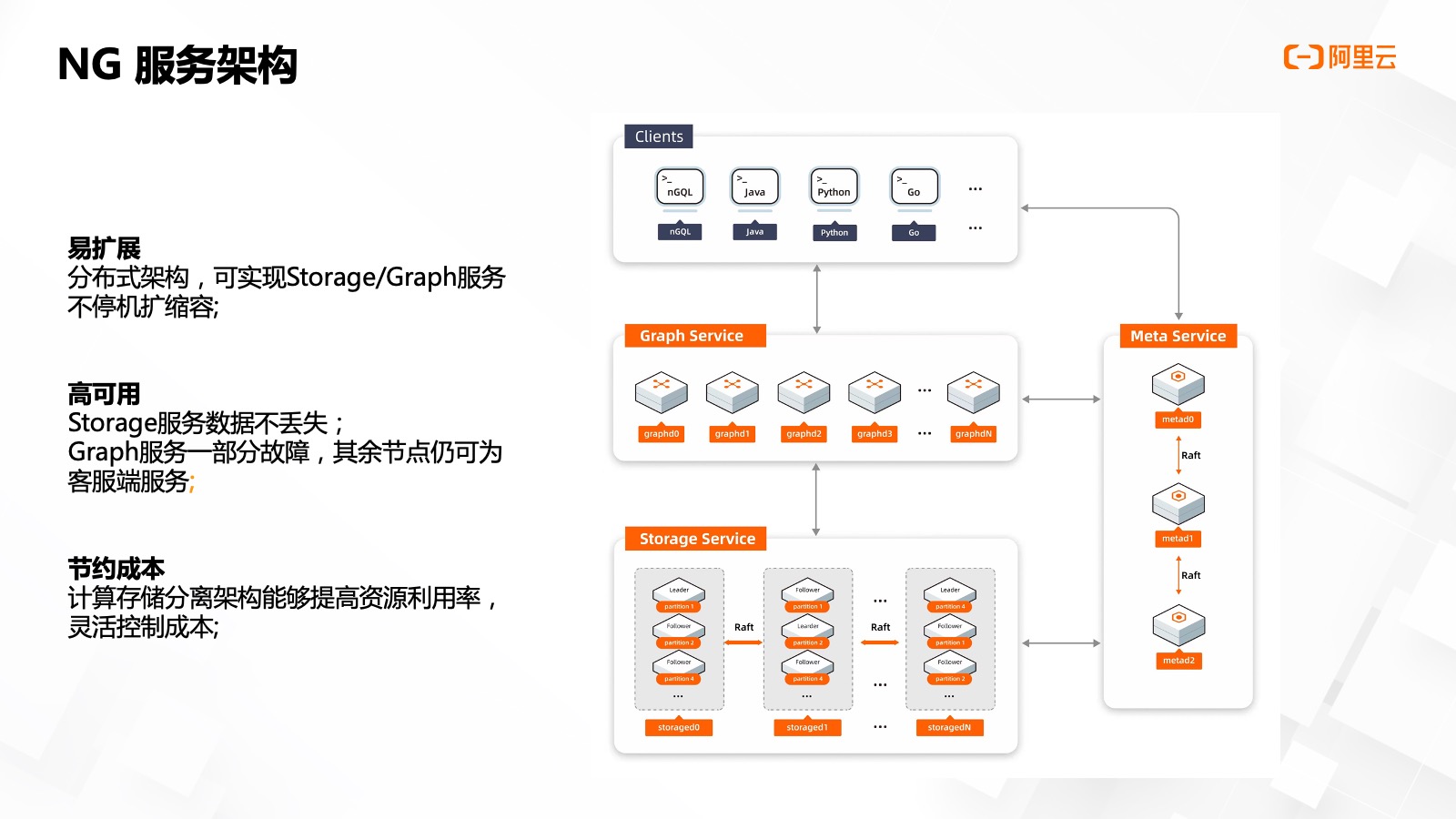
因為眾安沒有獨立機房,,所有的服務均依賴于阿里云金融云,,基于阿?云 ECS 的能力,可以快速實現(xiàn)服務器以及服務器上存儲資源的彈性擴收容,。實際部署中,,我們將 graphd 跟 mated,、 storaged 進行了分開部署,避免大量查詢導致內(nèi)存過高,,影響到其他圖數(shù)據(jù)服務的穩(wěn)定性,。
graphd 占用了 2 臺 4C 8G 服務器,metad/storaged 占用了 3 臺 4C 16G 服務器,。當前資產(chǎn)平臺的實體數(shù)量在 2,500w 個左右,,邊數(shù)據(jù)在 4左右,主要為數(shù)據(jù)集類型數(shù)據(jù),。
我們使用每臺 ECS 使用了兩塊 200G 的 ESSD 進行存儲,,根據(jù)悅數(shù)的推薦,磁盤的數(shù)量越多,,圖空間 Partition 的擴展的數(shù)量就可以越多,,可以獲得更好的并發(fā)處理能力。
眾安在悅數(shù)圖數(shù)據(jù)庫中的模型設(shè)計
下面介紹一下眾安基于悅數(shù)圖數(shù)據(jù)庫的模型設(shè)計,。
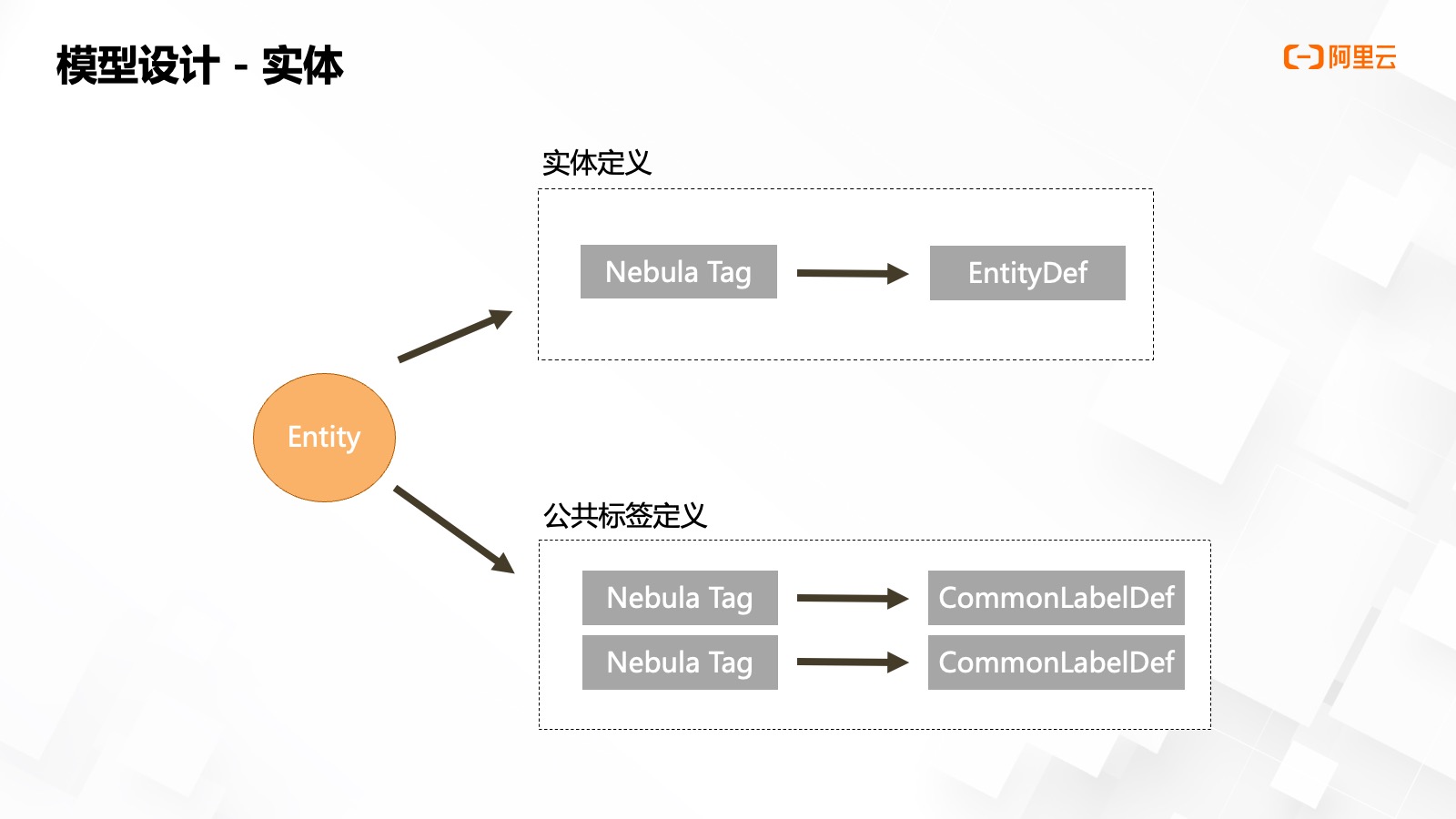
對于實體定義來說,,對應悅數(shù)圖數(shù)據(jù)庫的某一個 Tag,其相對于其他圖數(shù)據(jù)庫類似于 Label 概念,,就是某個屬性集的名稱,,通過 Tag 可以更快檢索倒到某一個實體點下的屬性,類型定義的 Tag 必須同這一類型的點 ID 進行強綁定,,注冊時需要進行相關(guān)校驗,。另一個屬性集的概念是公共標簽,公共標簽可以做很多事情,,比如業(yè)務屬性集,、實體標簽等。公共標簽在 NebulaGraph 當中也對應一個 Tag,,這個 Tag 可以綁定到多種不同的實體,,比如環(huán)境公共標簽,可以賦給 MySQL 數(shù)據(jù)源實體,,也可以賦給 MaxCompute數(shù)據(jù)源實體等,。
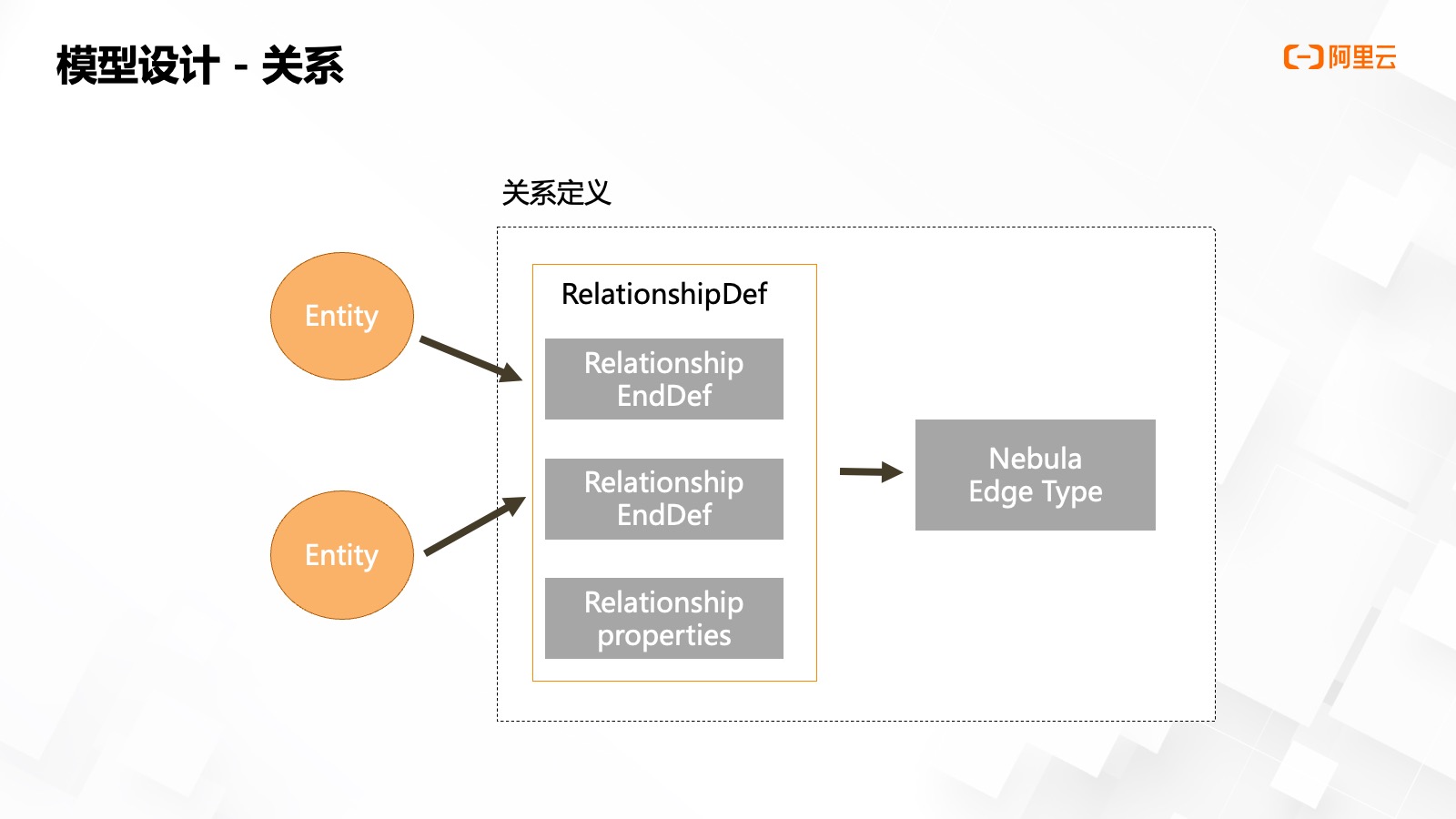
對于關(guān)系定義來說,對應悅數(shù)圖數(shù)據(jù)庫中的某個 Edge Type,,類型定義中的來源目標端點的實體類型,,必須同這一類型的點 ID 進行強綁定,注冊時需要進行相關(guān)校驗,。
對于數(shù)據(jù)隔離來說,,上述實體和關(guān)系模型,通過悅數(shù)圖數(shù)據(jù)庫的圖空間進行隔離,,在眾安內(nèi)部的多個租戶實體下,,比如保險、小貸,、科技等,,會在租戶初始化時創(chuàng)建指定圖空間,后續(xù)的類型定義均在租戶圖空間下進行,。
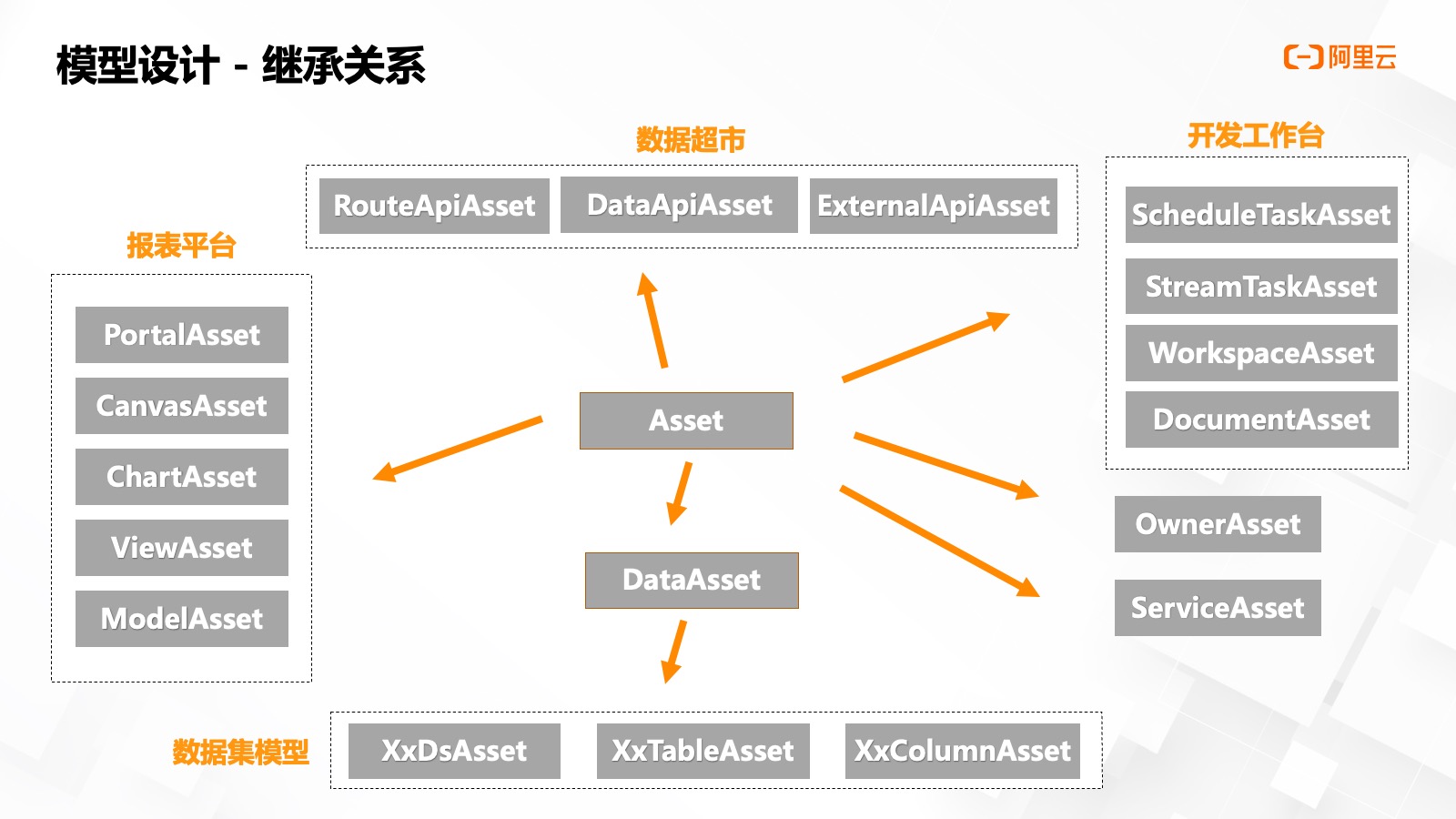
最后我們再來看?下模型設(shè)計的繼承關(guān)系,。我們所有的實體根節(jié)點是?個叫做 Asset 的實體定義,我們將一些公共屬性定義其中,,包括名稱,、展示名稱、備注,、類型等,;
基于 Asset 類型,我們實現(xiàn)了對接平臺的各種資產(chǎn)實體,,報表平臺里的模型,、視圖、畫布,、?戶等實體,,數(shù)據(jù)超市里的路由 API、數(shù)據(jù) API 以及外部擴展 API 等實體,,開發(fā)工臺里的調(diào)度任務,、流計算任務、工作空間,、文件等實體,,以及兩個比較特殊的資產(chǎn)屬主實體和服務資產(chǎn)實體。
另一個特殊的實體是數(shù)據(jù)集實體,,我們將不同數(shù)據(jù)源數(shù)據(jù)源,、表、列等信息均定義了獨立的資產(chǎn)實體定義,,以便實現(xiàn)不同數(shù)據(jù)源的差異化屬性展示,。
我們最終的全鏈路數(shù)據(jù)資產(chǎn),均是通過數(shù)據(jù)集及其子類自定義實現(xiàn)串聯(lián),,從而實現(xiàn)跨平臺的鏈路分析,。比如調(diào)度作業(yè)的庫表血緣,可以關(guān)聯(lián)到報表平臺的數(shù)據(jù)模型,,也可以關(guān)聯(lián)到數(shù)倉的 Data API 依賴的 Table Store 的某張表等等,。
03 未來展望
2022年年底,眾安基本上已經(jīng)實現(xiàn)了各個平臺的各種資產(chǎn)的注冊跟上報的過程,。
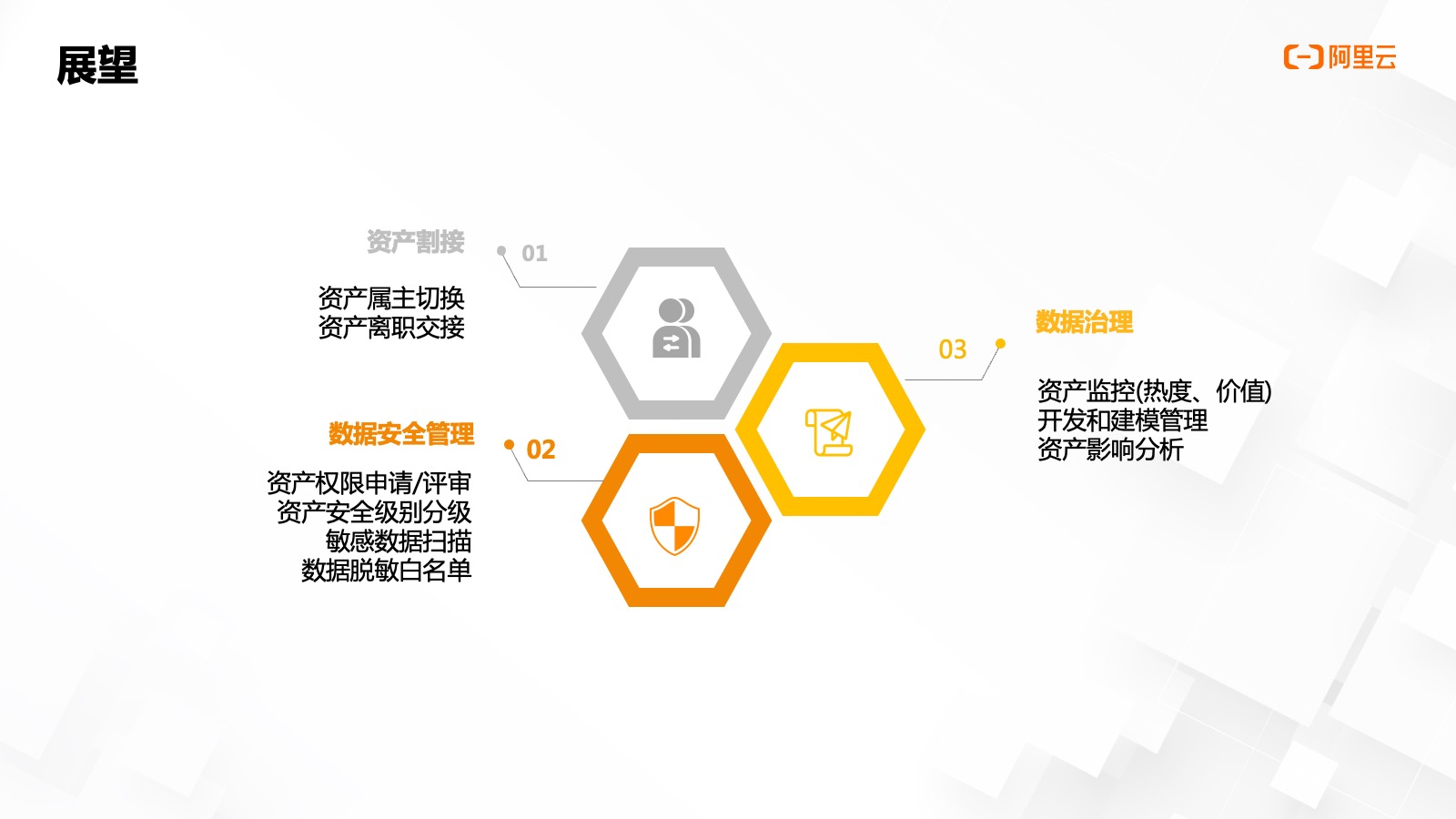
2023年,,我們將在圍繞數(shù)據(jù)資產(chǎn)割接,、數(shù)據(jù)安全管理和數(shù)據(jù)治理三個方面進行擴展性開發(fā)。
- 數(shù)據(jù)資產(chǎn)割接,,將站在用戶實體的角度上,,快速識別個人關(guān)聯(lián)的數(shù)據(jù)資產(chǎn),時間屬主資產(chǎn)切換和離職交接功能,。
- 數(shù)據(jù)安全管理,,基于資產(chǎn)平臺的能力做出多種擴展,遷移內(nèi)部老元數(shù)據(jù)系統(tǒng)的表分級,、權(quán)限審批功能,;內(nèi)部脫敏規(guī)則配置平臺及 SDK,擴展支持基于表分級數(shù)據(jù)加密和白名單策略等,。
- 數(shù)據(jù)治理,,基于資產(chǎn)平臺的全鏈路血緣分析能力,觀察資產(chǎn)熱度,、使用等關(guān)鍵指標,,清理無效作業(yè)和重復計算作業(yè),實現(xiàn)降本增效,,減少云平臺使用費用,。
要來感受同眾安科技一樣的圖數(shù)據(jù)庫體驗嘛?悅數(shù)圖數(shù)據(jù)庫 x 阿里云計算巢現(xiàn) 30 天免費使用中,,點擊鏈接來搭建自己的資產(chǎn)管理系統(tǒng)吧,!




