首頁>博客>技術(shù)干貨行業(yè)實踐>圖 + AI 在金融行業(yè)的應(yīng)用及技術(shù)前瞻|應(yīng)用分享
圖 + AI 在金融行業(yè)的應(yīng)用及技術(shù)前瞻|應(yīng)用分享
本文整理自悅數(shù)圖數(shù)據(jù)庫-資深技術(shù)專家-古思為 在《圖創(chuàng)價值·圖+AI 在金融反欺詐行業(yè)應(yīng)用》現(xiàn)場的分享,查看原文 點擊此處。

非常開心有機會跟大家做一個分享。今天的主題是圖技術(shù)+ AI 在金融反欺詐領(lǐng)域的應(yīng)用,,我的分享內(nèi)容與之呼應(yīng)——就是 Graph 和 AI 結(jié)合金融領(lǐng)域的一些案例以及最近我們在做的一些大語言模型及前沿技術(shù)工具,讓我們看看每一個場景里這些新技術(shù)能給行業(yè)帶來什么樣的變化。
如何用圖的方式做欺詐檢測
隨著金融業(yè)務(wù)線上化的普及,,現(xiàn)在許多用戶會在金融 APP 客戶端上申請信用貸款,然后金融機構(gòu)的系統(tǒng)里面就會關(guān)聯(lián)到申請人的一些信息,,比如聯(lián)系人電話以及工作公司等,。首先給大家展示的就是這個線上借貸場景的圖模型,目前比較快速直接的方式是把這個問題以圖的形式去表達(dá),,然后就可以去做一些基礎(chǔ)的圖模式匹配,。
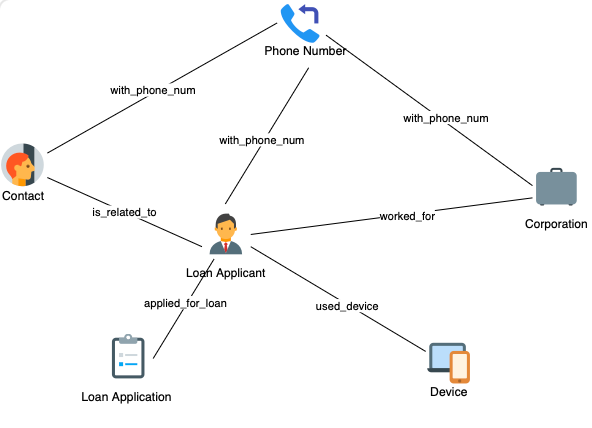
- 線上借貸場景的圖模型
另外一個就是用標(biāo)簽傳播(Label Spread)的方法去解決其他問題。比如說,,從一個點開始找到符合條件的單子,,然后我發(fā)現(xiàn)他用到了另一個設(shè)備,這個設(shè)備是跟另一個單子共享的——這個信息如果能夠被金融機構(gòu)以毫秒級的速度獲得的話,不僅可以給領(lǐng)域?qū)<夷脕碜鲆恍┘皶r的洞察分析,,而且可以把它放在線上系統(tǒng)里作為提示風(fēng)險的一個衡量指標(biāo),。
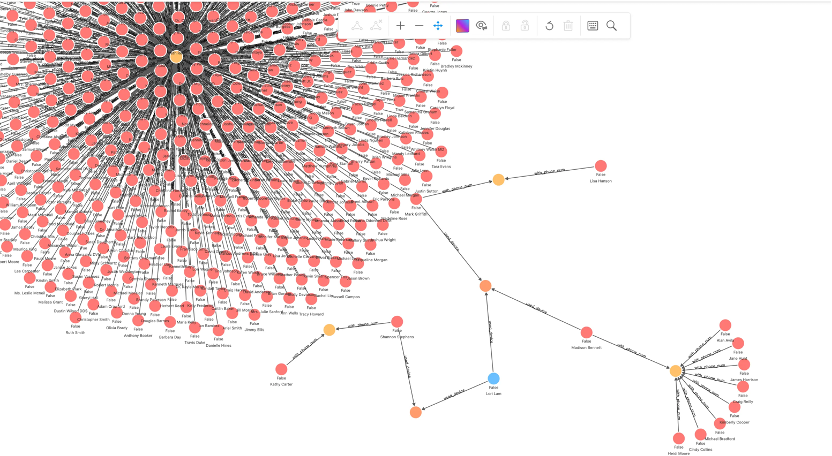
- 通過圖查詢語句來搜索群控設(shè)備
那隨之而來就有個問題,如果我們標(biāo)記的高風(fēng)險數(shù)據(jù)量不夠的話,,怎么能夠提高這種特征風(fēng)控的效果呢,?
這里有另一個方法叫「標(biāo)簽傳播」(Label Spread)。它其實基本上利用了這個標(biāo)簽傳播 Label Propagation 的方法,,但這個算法目標(biāo)有一點變化,,我們是想要基于少量標(biāo)注的有高風(fēng)險的信息在圖上做迭代,類似于標(biāo)簽傳播,,但我們目的并不是找出社區(qū),,而是擴(kuò)展灰度的標(biāo)簽。這個信息在有時候也是有提示意義的,,它可以作為單獨的一個參考,,給更復(fù)雜的風(fēng)控系統(tǒng)當(dāng)作一個考量維度。
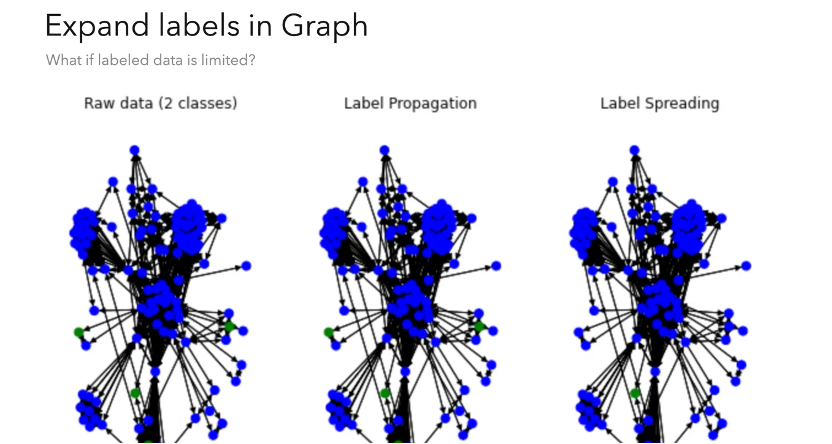
除此之外的話還有一些利用到「機器學(xué)習(xí)」的方法,,最直接也是比較傳統(tǒng)的方法,,就是純利用數(shù)據(jù)屬性去做一些分類的模型,然后去定期地識別高風(fēng)險的交易,。當(dāng)我們把圖屬性也考慮進(jìn)來,,比如說下面的 Demo,我們可以把社區(qū)聚集的信息也作為圖特征(Feature)的一部分,,我們分出少量的社區(qū),,然后把這個社區(qū)的數(shù)字用 bitwise 的方式把它作為 feature。
我剛剛點了 Louvain 算法之后就可以很清晰地看到有聚集性的集群,,不同社區(qū)可以使用不同的顏色去區(qū)分,,這部分信息是可以作為傳統(tǒng)機器學(xué)習(xí)里邊的特征考量進(jìn)來的,因為它體現(xiàn)了一定情況下這些實體之間潛在的關(guān)聯(lián)遠(yuǎn)近程度,,而這個信息在風(fēng)險預(yù)測領(lǐng)域是非常有用的,。

除此之外,比如說我們跑一個比較常見的節(jié)點重要度算法—— PageRank 算法,,就可以看到這里最重要的就是「設(shè)備」 這個點跟很多信息都有關(guān)聯(lián),,通過 PageRank 值能夠體現(xiàn)節(jié)點被連接的程度,這個量化的值作為圖特征也是被證明有效的,。
另外還有在機器學(xué)習(xí)領(lǐng)域比較流行的圖神經(jīng)網(wǎng)絡(luò)(GNN),,它是通過一種表示的形式和方法使得圖上鄰接的關(guān)系,以及它在這個函數(shù)迭代的過程,,能夠充分地用點和其他點相鄰的關(guān)系以及點上屬性給體現(xiàn)出來,,所以跟之前只是用圖特征這幾個維度數(shù)字作為輸入相比,,能更好地把圖上點與點之間的關(guān)系利用起來。
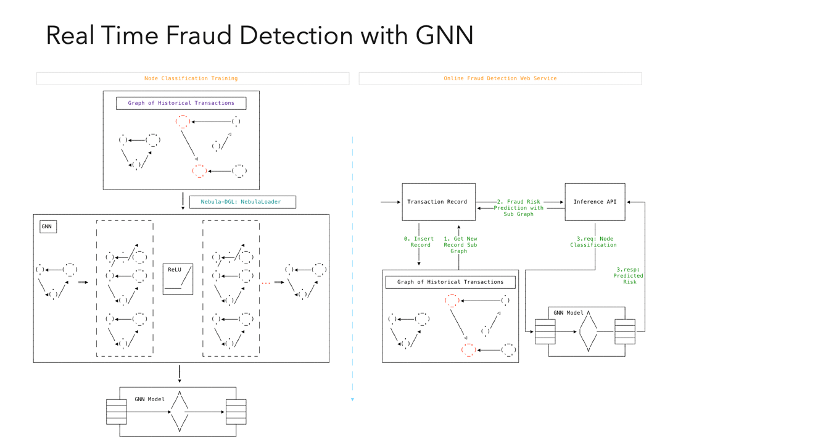
這個例子我之前也分享過,,圖左邊的 GNN 模型是一個節(jié)點的分類模型,,目標(biāo)就是預(yù)測圖上任意一個點是否有風(fēng)險的分類;右邊就是線上系統(tǒng)最后落地的樣子,。我們建立好圖建模信息之后,,根據(jù)模型里面標(biāo)注的提示高風(fēng)險的點進(jìn)行訓(xùn)練,模型訓(xùn)練好之后輸入任意一個子圖,,它都可以預(yù)測出新的子圖上任意一個點的風(fēng)險值,,所以在一些金融風(fēng)控的線上系統(tǒng)中每發(fā)現(xiàn)一個新的交易或者是一個請求過來,我們就把這個信息插到圖譜上,,這樣就可以實時進(jìn)行欺詐檢測,。
圖如何幫助大語言模型的應(yīng)用落地
第二部分給大家簡單介紹一下圖(Graph)和大語言模型(LLM)的結(jié)合點。
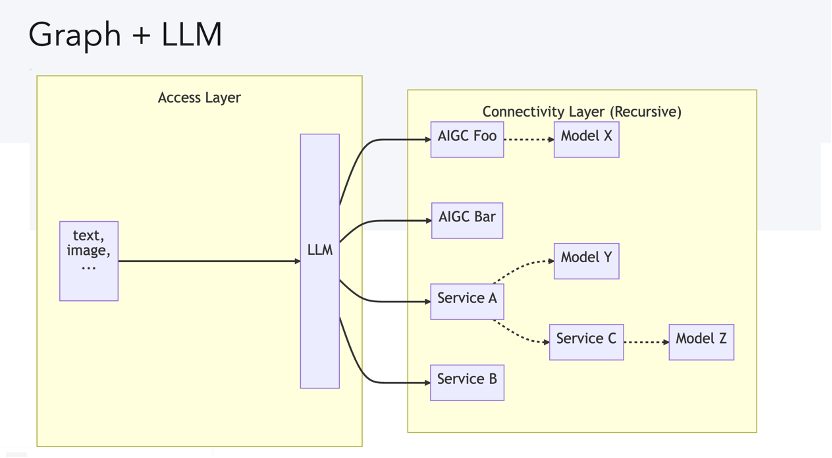
這張圖是講現(xiàn)在我們在大語言模型引領(lǐng)和賦能下可以怎樣實現(xiàn)比較智能的圖應(yīng)用,?;旧衔野阉譃榻尤雽雍瓦B接層,當(dāng)然連接層里邊是可以迭代的,,每個小部分還可以內(nèi)嵌一個大語言模型,然后提示給大語言模型,,比如說 Cloud 或者是 OpenAI 的 GPT 的某一個版本,,它就可以理解你的意圖,并且直接回答你的問題,,也可以根據(jù)你的意圖再去調(diào)用我們已有的其他服務(wù)或者模型,。
如果你想要做一些創(chuàng)造性的探索,它就可以幫你調(diào)某一個生成模型,,比如說你想做某個服務(wù)的查詢,,那像 OpenAI 有 API 或者是你自己用一些方式就可以去訪問互聯(lián)網(wǎng)。有了大語言模型這一層,,使得以前比如專門做 NLP 或者翻譯等等很多以前看起來很難被智能化又非常昂貴的領(lǐng)域,,現(xiàn)在都有了更多的備選方案。
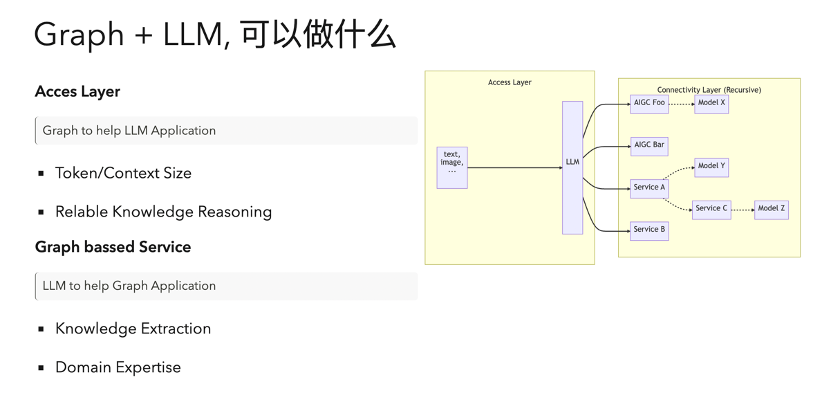
在這里,,圖數(shù)據(jù)庫可以做什么,?
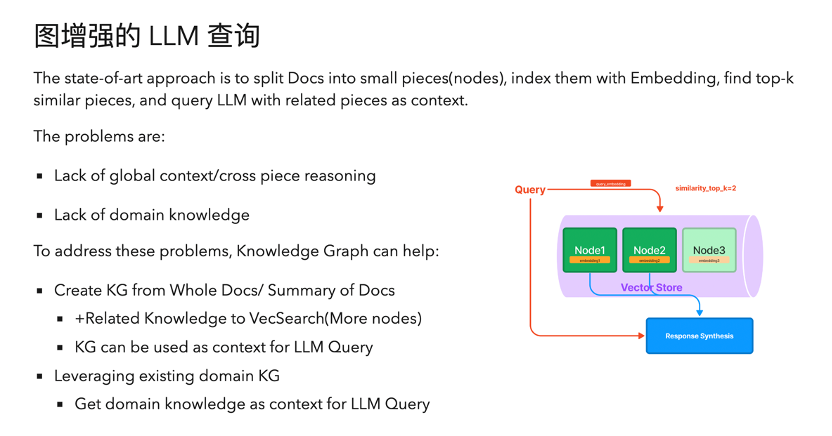
首先,我們可以在接入層做一點事情,。比如說我們想要在既定的一個大語言模型上做給定領(lǐng)域的知識問答,,一個常見的情況就是我們需要額外同步專有的領(lǐng)域知識,但是這個同步是有限制的,,不是所有模型都支持,,而且有的時候比較昂貴,。比如說我們要基于一個 100 兆的 PDF 作為上下文的背景知識來問問題,常見的方式就是把它給分割開來,,比如說分成 100 份,,然后每份的內(nèi)容把它總結(jié)起來,然后放在 Vector search 里面做一個嵌入,。
具體落地來說,,比如你問一個問題,他會把這個問題跟你分割的每一個小塊的信息在向量空間里做一個距離的搜尋,,取出離得最近的比如三塊的相關(guān)上下文內(nèi)容,,而把這個上下文和你這個問題一起丟給大語言模型——這是現(xiàn)在最直接的一個方法,但是它還是有問題,。
首先就是這種方法雖然緩解了上下文過多的問題,,但是也會丟失部分你要額外增加的背景知識,而且你缺失了節(jié)點與節(jié)點之間的關(guān)聯(lián),,是個割裂的知識塊,。
其次,我們知道大語言模型有時候的回答不是穩(wěn)定和可重現(xiàn)的,,也不是那么專業(yè)可信,。舉個例子,如果我們想要做一個在醫(yī)院里處理分診問題的智能問答機器人,,這種情況下即使用非常智能的大語言模型,,哪怕只有萬分之一的可能會給出很奇怪的結(jié)果,所帶來的負(fù)面影響都是不能承受的——因為它會影響人的生命和健康,。這種領(lǐng)域的話,,傳統(tǒng)方法其實是利用專業(yè)的知識圖譜(Knowledge Graph)基于基本的模式匹配之后給出一個確定的推理。
這時候就可以用圖(Graph) 去解決剛剛提到兩個問題,,一個是當(dāng)我們用 Vector search 去做切分的時候,,我們可以利用知識圖譜提供全局視野。另一個就是我們在基于某個非結(jié)構(gòu)化的海量上下文做問答的時候,,比如說一個很大的網(wǎng)站和文檔知識庫,,同時接入已有的知識圖譜話,就可以提供一個相對來說比較高可信度的推理,。

這個圖就是剛剛我提到的知識嵌入(embedding)部分引入圖技術(shù),, 另一部分其實大語言模型本身是可以幫助圖的,就是我們?nèi)ピO(shè)置一個知識圖譜的時候,,知識的梳理其實有時候是涉及到理解力的,,這個時候大語言模型是能夠起到幫助作用的,而且有時候能夠替代一些以前必須得要領(lǐng)域?qū)<乙氲沫h(huán)節(jié),,相對來說更加的高效和自動化,。
關(guān)于前面提到的大語言模型的查詢層,,實際上這個領(lǐng)域來說,到今天比較先進(jìn)的方式是有一些人做了一些封裝,,當(dāng)然你可以自己直接從頭寫代碼去,,中間只要插一個 Vector search 就能做 embedding 的事情。但是有些 dirty work 需要你額外去做,,其實大家都做重復(fù)的一塊,。再一個就是有的時候它中間不只是僅僅的去分割然后抽取,其實這是大體的思路,,但實際上落地的時候會有很多小的細(xì)節(jié)的優(yōu)化途徑,,所以這個領(lǐng)域其實有一些抽象的中間層的庫,比較流行的,,比如叫 Langchain 的一個項目,。
其次還有個項目叫 LLAMA Index,大家感興趣的話可以去了解一下,,基本上我給 LLAMA 外部知識圖譜這個概念,,它能夠在建立正常的設(shè)置參數(shù)的過程中,同步地把信息里邊的知識總結(jié)出來,,然后導(dǎo)入到外部的知識圖譜中去,。
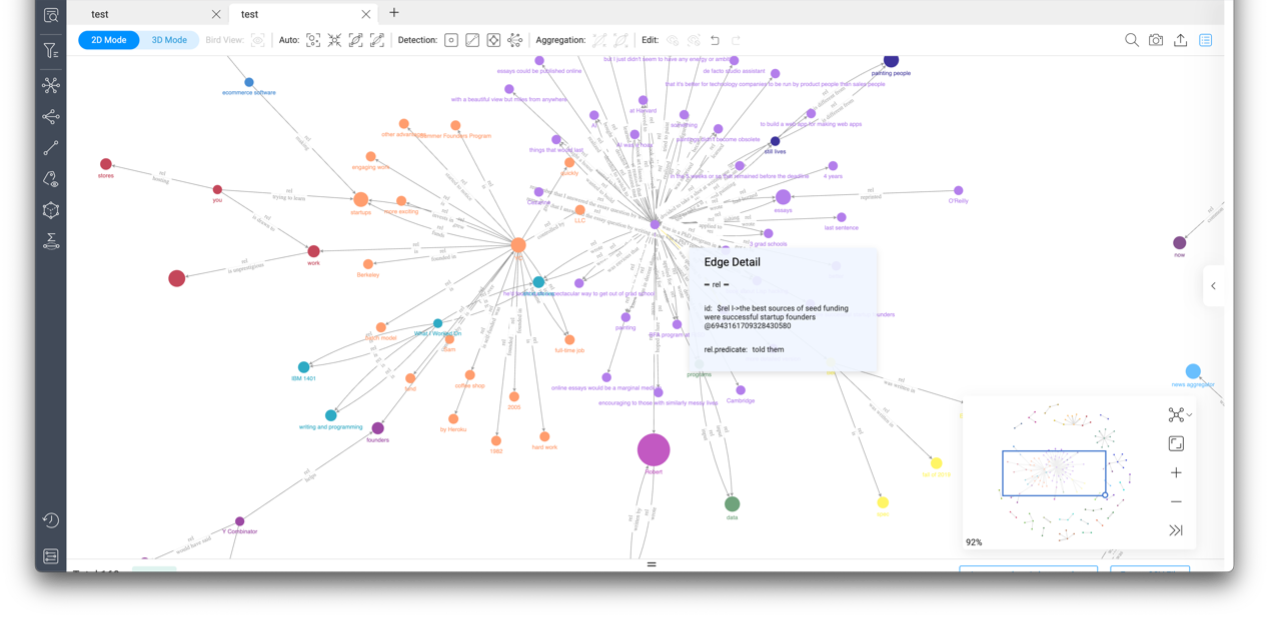
另外,大語言模型也可以幫助很多系統(tǒng)去掉昂貴的人力投入環(huán)節(jié),。這里邊有幾個方面,,一個是在知識抽取的過程中,我受到啟發(fā)很有名的項目叫 GraphGPT,。基本上我就告訴大語言模型,,你現(xiàn)在要幫我做一個知識解析的過程,,就是你要從這一段文字里面解析出主謂賓的知識結(jié)構(gòu)。在這個案例里,,我給他了一段關(guān)于哈利波特的文字,,最后他就幫我返回了一個一段 Json,就描述了這一段話里面的三元組的知識,。最后我們把它渲染出來,,就是一個關(guān)于哈利波特的知識圖譜。

這只是一個很小的 demo,,但圖譜其實表現(xiàn)地也很自然,,大家只要做圖都會想到用大語言模型建立一個知識圖譜,現(xiàn)在跟以前的情況和需要的投入完全不同了,。
另外一個大語言模型幫助到圖(Graph)的一個例子是是我另一個項目,,這個項目寫得很早,,基本上就是你提供給我圖上的 schema 以及你想要做的 query,它就可以幫你實時的去寫圖數(shù)據(jù)庫的查詢,。
當(dāng)然了,,未來這些能力都會嵌在我們「悅數(shù)圖數(shù)據(jù)庫」各種各樣的產(chǎn)品里,也是蠻有意思,,大家如果感興趣的話,,可以找這個 Demo 玩一下。

最后我想說其實圖天然是有可解釋性的,,舉個例子,,這個是我的另一篇文章里邊的例子,但是這個系統(tǒng)是一個推薦系統(tǒng),。我們知道上個禮拜 OpenAI 有篇文章講他們怎么利用 GPT-4 去為他們的 GPT-2 模型做模型里的可解釋性的分析,,還挺酷的,其實利用圖的話也可以做一定的努力,。
這個例子,,其實就是我們一個很黑盒的推薦系統(tǒng)給出的結(jié)果,只要有這個結(jié)果里面涉及到實體做一個路徑查詢,,我們通過圖數(shù)據(jù)庫是可以給出一定的可解釋性的,,蠻有意思的。
悅數(shù)圖數(shù)據(jù)庫:打造更順滑高效的 Graph + AI 工具鏈
最后一部分給大家介紹 Graph + AI 時代,,悅數(shù)會打造怎么樣的產(chǎn)品以及能提供什么樣的方法論,。
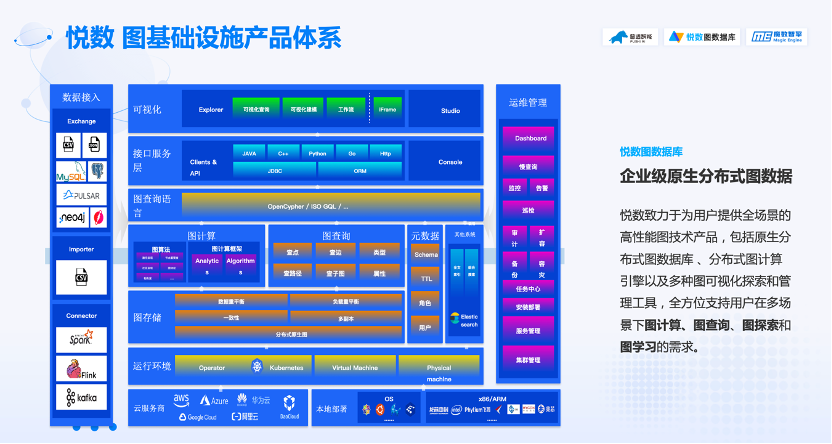
首先,悅數(shù)圖數(shù)據(jù)庫是原生分布式的,,所以你可以很輕松地實時處理很大的數(shù)據(jù)集群,。因為本質(zhì)上,悅數(shù)圖數(shù)據(jù)庫的計算與存儲是分離的,,它的計算層是無狀態(tài)的,,這使得我們做了很多不同的計算層,其實對于圖來說都只是另一個異構(gòu)的查詢或計算層而已,,因此它的可擴(kuò)展性非常好,。?
除了內(nèi)核數(shù)據(jù)庫之外,悅數(shù)還提供了自研的圖算法工具,,我們可以在這上面自己實現(xiàn)或者是跑現(xiàn)有內(nèi)置的各種圖的算法,,目前也很受大家歡迎。其中「悅數(shù)圖分析」是我們推出的一個圖算法工具,,這個是只有企業(yè)版本,。它主要的優(yōu)勢是有更高的資源使用率,然后性能也會更好一些,。
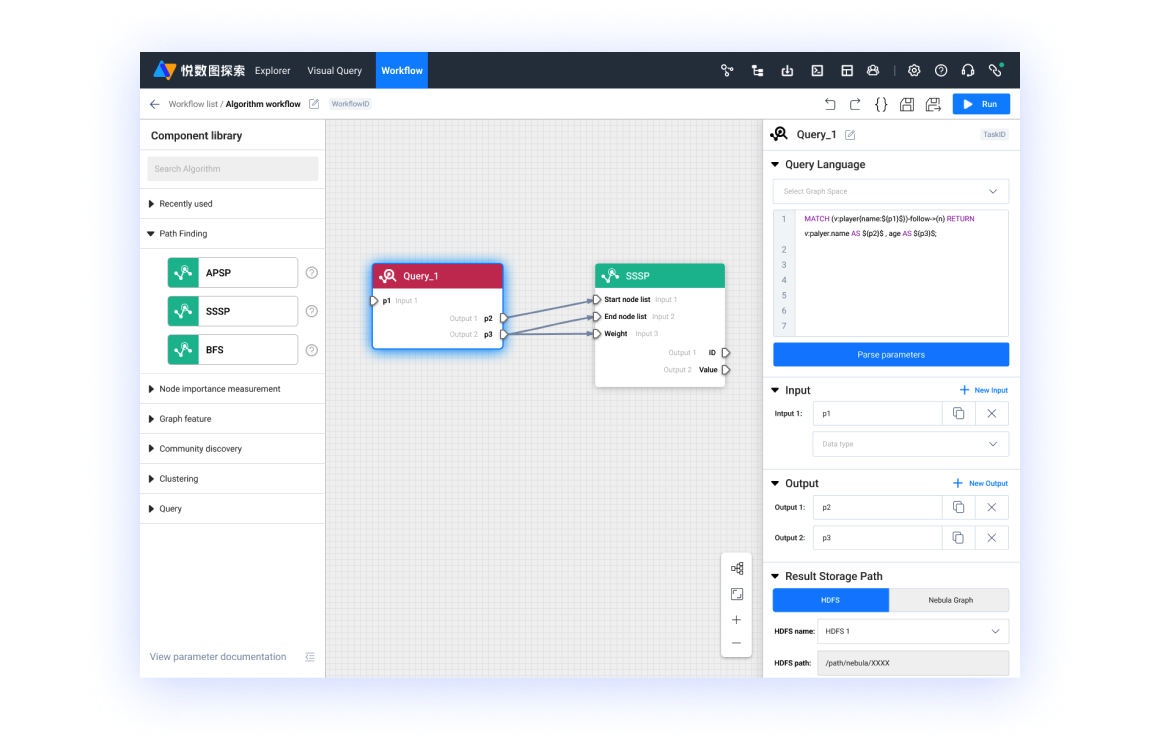
- 悅數(shù)可視化產(chǎn)品中的工作流操作展示
「悅數(shù)圖分析」還有一個優(yōu)勢就是它能跟我們的可視化的工具有非常好的結(jié)合,。剛才給大家演示的 Demo 就是在悅數(shù)的可視化工具里邊實現(xiàn)的,。大家可以利用工作流快速去驗證一個想法,之后再在數(shù)據(jù)規(guī)模更大的情況下再進(jìn)一步去做 Benchmark 或驗證,,最后落地到真實的場景,。比如這一步取什么樣的數(shù)據(jù)/怎么取,下一步做什么樣的運算,,這一步運算的輸出和另一個運算輸出指向下一個任務(wù)后再輸出到哪里,,這些過程在悅數(shù)的工具體系里都可以拖拉拽、零代碼地實現(xiàn),。
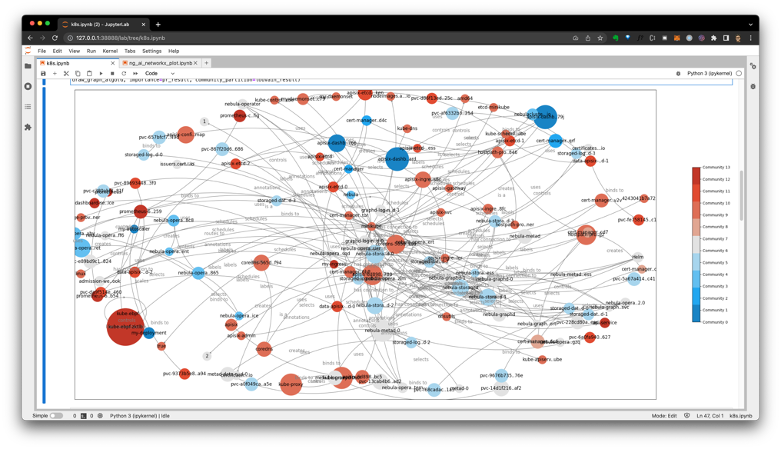
- 基于 AI 工具生成的可視化圖數(shù)據(jù)集
然后,,悅數(shù)也在做一些跟 AI 以及 GNN 結(jié)合的工具類產(chǎn)品。在這里給大家介紹的一個項目叫「AI Suite」,,它其實是一個面向 Graph 和 AI 的一個 high level 的 API,,它是個 Python 的庫,通過幾行代碼就可以把悅數(shù)圖數(shù)據(jù)庫上的信息讀到這個圖里邊,,然后緊接著像這兩行就直接跑了一個 PageRank 算法,,然后 AI 工具就可以自動把它畫出來。
另外還有跟最流行的兩個圖神經(jīng)網(wǎng)絡(luò)(GNN)的框架之一,,亞馬遜和紐約大學(xué)開源的圖深度學(xué)習(xí)框架 DGL 合作的項目,,你可以很容易地把悅數(shù)圖數(shù)據(jù)庫里面的圖給它序列化成 DGL 的對象,然后在此基礎(chǔ)之上就可以很容易地做,,比如說鏈路的預(yù)測,、節(jié)點的分析等等。比如說我訓(xùn)練好鏈路預(yù)測的模型之后,,取一個點和跟它沒有相連的點,,然后把數(shù)據(jù)這個喂給模型就可以做預(yù)測,比如某個人有可能想要看哪個電影,,也是一個蠻有意思的一個工具,。
以上就是我分享的內(nèi)容,感謝大家的時間,,歡迎大家關(guān)注我們的公眾號和官網(wǎng),目前悅數(shù)圖數(shù)據(jù)庫在阿里云上支持 免費試用,,歡迎大家進(jìn)一步了解,,謝謝。




